介紹 Gateway API 推理擴充套件
現代生成式 AI 和大語言模型(LLM)服務在 Kubernetes 上帶來了獨特的流量路由挑戰。與典型的短時、無狀態 Web 請求不同,LLM 推理會話通常是長時間執行、資源密集且部分有狀態的。例如,單個由 GPU 支援的模型伺服器可能會保持多個推理會話活躍,並維護記憶體中的 Token 快取。
專注於 HTTP 路徑或輪詢的傳統負載均衡器缺乏處理這些工作負載所需的專業能力。它們也沒有考慮模型標識或請求的關鍵性(例如,互動式聊天與批處理作業)。組織通常會拼湊臨時解決方案,但缺少一種標準化的方法。
Gateway API 推理擴充套件
Gateway API Inference Extension 的建立旨在填補這一空白,它建立在現有的 Gateway API 之上,增加了推理專用的路由功能,同時保留了熟悉的 Gateways 和 HTTPRoutes 模型。透過在你現有的閘道器上新增一個推理擴充套件,你可以有效地將其轉變為一個 Inference Gateway(推理閘道器),從而能夠以“模型即服務”的理念自託管 GenAI/LLM。
該專案的目標是改進和標準化整個生態系統中針對推理工作負載的路由。關鍵目標包括實現模型感知路由、支援按請求區分關鍵性、促進安全的模型釋出,以及根據即時模型指標最佳化負載均衡。透過實現這些目標,該專案旨在降低 AI 工作負載的延遲並提高加速器(GPU)的利用率。
工作原理
該設計引入了兩個新的自定義資源(CRD),它們具有不同的職責,每個都與 AI/ML 服務工作流中的特定使用者角色相對應:
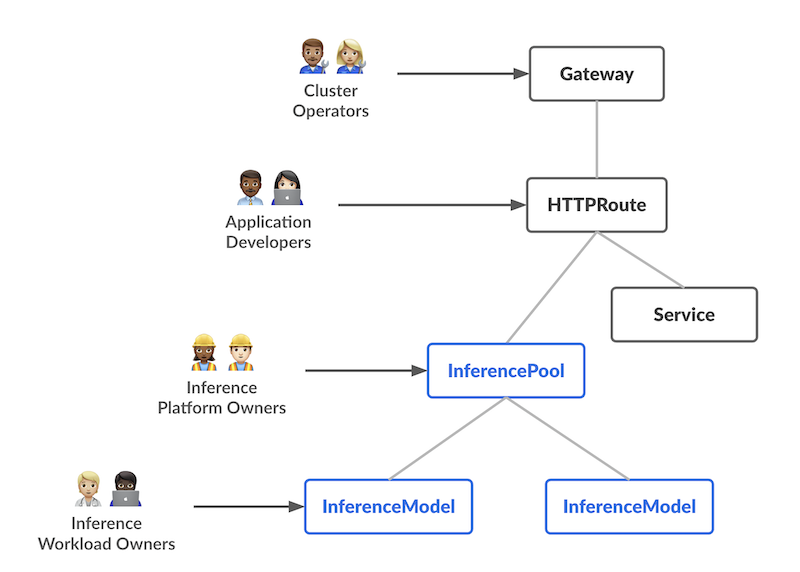
InferencePool 定義了一個在共享計算資源(例如 GPU 節點)上執行的 Pod 池(模型伺服器)。平臺管理員可以配置這些 Pod 的部署、擴充套件和均衡方式。InferencePool 確保資源使用的一致性,並執行平臺範圍的策略。InferencePool 類似於 Service,但專門針對 AI/ML 服務需求,並能感知模型服務協議。
InferenceModel 一個由 AI/ML 所有者管理的面向使用者的模型端點。它將一個公共名稱(例如 "gpt-4-chat")對映到 InferencePool 中的實際模型。這使得工作負載所有者可以指定他們想要服務的模型(以及可選的微調),以及流量切分或優先順序策略。
總而言之,InferenceModel API 讓 AI/ML 所有者管理**提供什麼服務**,而 InferencePool 讓平臺操作員管理**在哪裡以及如何提供服務**。
請求流程
請求流程建立在 Gateway API 模型(Gateways 和 HTTPRoutes)之上,中間增加了一個或多個額外的推理感知步驟(擴充套件)。以下是使用端點選擇擴充套件(Endpoint Selection Extension, ESE)的請求流程的高階示例:
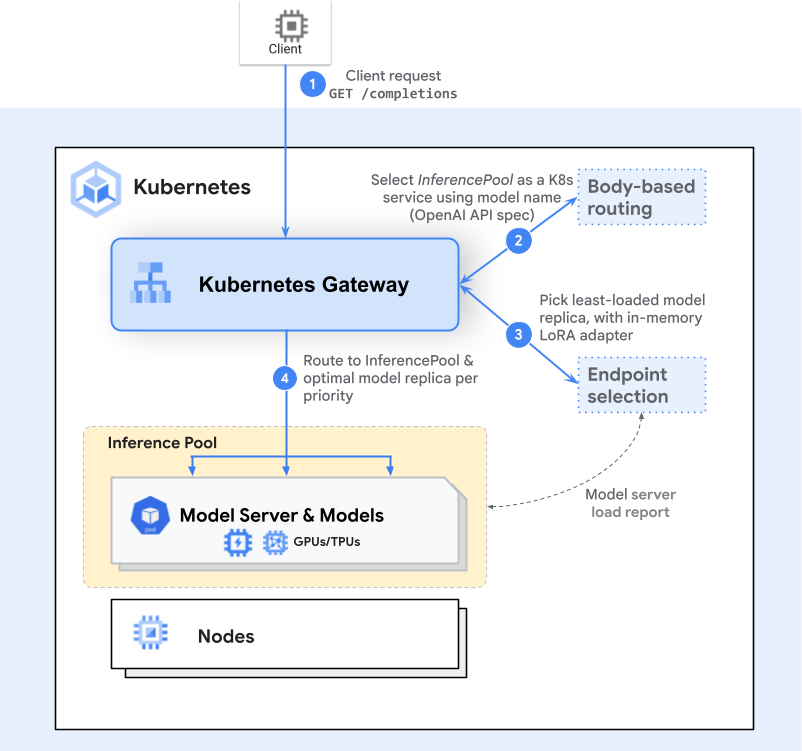
閘道器路由
客戶端傳送一個請求(例如,一個到 /completions 的 HTTP POST 請求)。閘道器(如 Envoy)檢查 HTTPRoute 並識別匹配的 InferencePool 後端。端點選擇
閘道器不是簡單地將請求轉發到任何可用的 Pod,而是諮詢一個特定於推理的路由擴充套件——端點選擇擴充套件——來選擇可用的最佳 Pod。該擴充套件會檢查即時的 Pod 指標(佇列長度、記憶體使用情況、已載入的介面卡)以選擇最適合該請求的 Pod。推理感知排程
被選中的 Pod 是那個在給定使用者關鍵性或資源需求的情況下,能夠以最低延遲或最高效率處理請求的 Pod。然後,閘道器將流量轉發到該特定的 Pod。
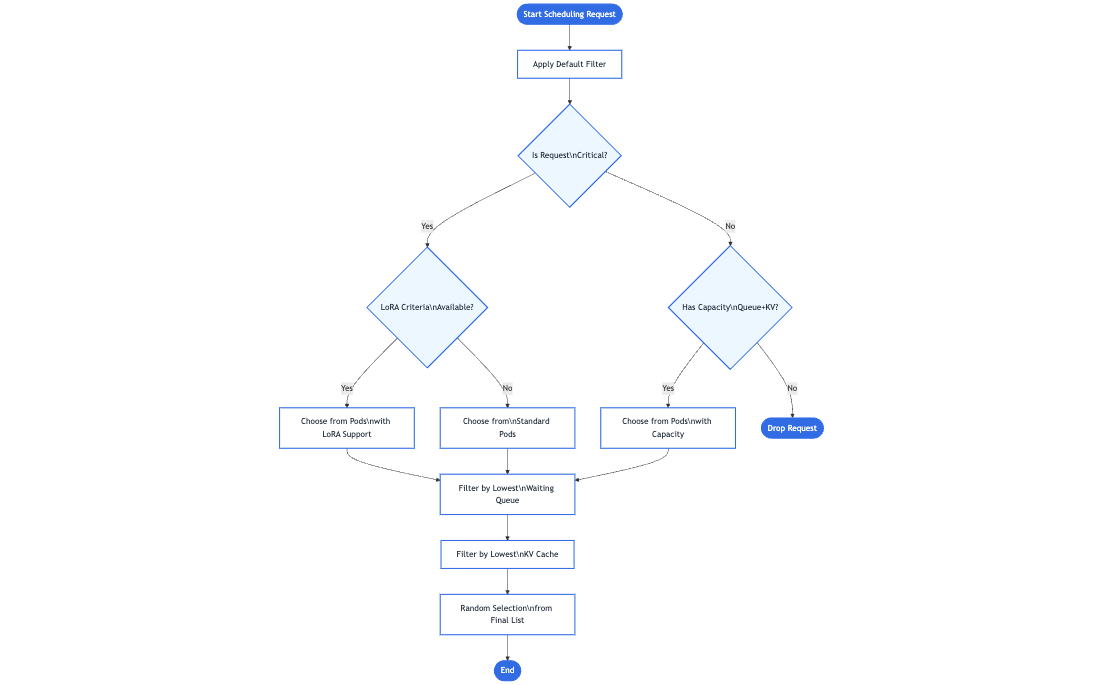
這個額外的步驟提供了一種更智慧、模型感知的路由機制,對客戶端來說仍然感覺像一個正常的單次請求。此外,該設計是可擴充套件的——任何 Inference Gateway 都可以透過額外的推理專用擴充套件來增強,以處理新的路由策略、高階排程邏輯或專門的硬體需求。隨著專案的不斷發展,我們鼓勵貢獻者開發與相同底層 Gateway API 模型完全相容的新擴充套件,從而進一步擴充套件高效和智慧 GenAI/LLM 路由的可能性。
基準測試
我們針對一個基於 vLLM 的模型服務部署,將此擴充套件與標準的 Kubernetes Service 進行了評估。測試環境由多個執行 vLLM(版本 1)的 H100 (80 GB) GPU Pod 組成,部署在一個 Kubernetes 叢集上,包含 10 個 Llama2 模型副本。我們使用 延遲概況生成器(Latency Profile Generator, LPG)工具生成流量並測量吞吐量、延遲和其他指標。ShareGPT 資料集用作工作負載,流量從每秒 100 次查詢 (QPS) 逐步增加到 1000 QPS。
關鍵結果
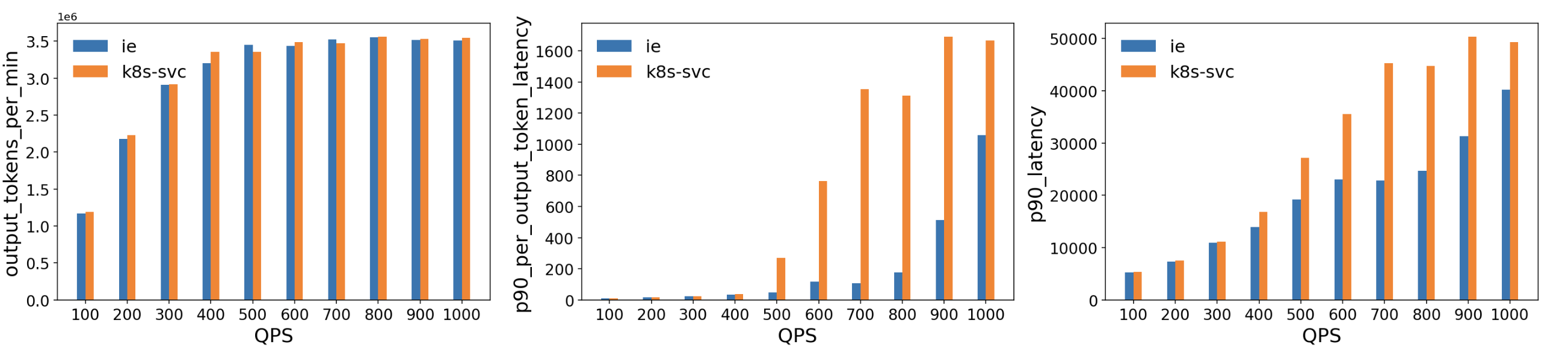
相當的吞吐量:在測試的 QPS 範圍內,ESE 提供的吞吐量與標準的 Kubernetes Service 大致相當。
更低的延遲:
- 每個輸出 Token 的延遲:ESE 在更高的 QPS(500+)下顯示出顯著更低的 p90 延遲,這表明其模型感知路由決策在 GPU 記憶體接近飽和時減少了排隊和資源爭用。
- 整體 p90 延遲:出現了類似的趨勢,與基線相比,ESE 降低了端到端的尾延遲,尤其是在流量增加到 400-500 QPS 之後。
這些結果表明,該擴充套件的模型感知路由顯著降低了由 GPU 支援的 LLM 工作負載的延遲。透過動態選擇負載最輕或效能最佳的模型伺服器,它避免了在使用傳統負載均衡方法處理大型、長時間執行的推理請求時可能出現的熱點問題。
路線圖
隨著 Gateway API Inference Extension 邁向正式釋出(GA),計劃中的功能包括:
- 針對遠端快取的字首快取感知負載均衡
- 用於自動化釋出的 LoRA 介面卡流水線
- 同一關鍵性級別內工作負載之間的公平性和優先順序
- 支援 HPA,可根據聚合的、每個模型的指標進行擴充套件
- 支援大型多模態輸入/輸出
- 額外的模型型別(例如,擴散模型)
- 異構加速器(在多種加速器型別上提供服務,並進行延遲和成本感知的負載均衡)
- 用於獨立擴充套件池的解耦服務
總結
透過將模型服務與 Kubernetes 原生工具對齊,Gateway API Inference Extension 旨在簡化和標準化 AI/ML 流量的路由方式。憑藉模型感知路由、基於關鍵性的優先順序劃分等功能,它幫助運維團隊平穩高效地向正確的使用者提供正確的 LLM 服務。
準備好了解更多資訊了嗎? 訪問專案文件深入瞭解,通過幾個簡單步驟嘗試一下 Inference Gateway 擴充套件,如果您有興趣為專案做貢獻,歡迎參與其中!