本文發表於一年多前。舊文章可能包含過時內容。請檢查頁面中的資訊自發布以來是否已變得不正確。
一個用於編排高可用性應用程式的自定義 Kubernetes 排程器
只要您願意遵守規則,在 Kubernetes 上部署和空中旅行都可以是相當愉快的體驗。大多數情況下,事情都會“按部就班”。然而,如果一個人有興趣帶著一隻必須活著的鱷魚旅行,或者擴充套件一個必須保持可用的資料庫,情況可能會變得更加複雜。甚至為此建造自己的飛機或資料庫可能更容易。拋開帶著爬行動物旅行不談,擴充套件一個高可用有狀態系統絕非易事。
擴充套件任何系統都包含兩個主要元件:
- 新增或移除系統將執行的基礎設施,以及
- 確保系統知道如何處理自身被新增和移除的額外例項。
大多數無狀態系統,例如 Web 伺服器,在建立時不需要知道它們的對等節點。而有狀態系統,包括像 CockroachDB 這樣的資料庫,必須與其對等例項協調並重新分配資料。幸運的是,CockroachDB 負責資料重新分配和複製。棘手的部分是如何在這些操作過程中容忍故障,透過確保資料和例項分佈在多個故障域(可用區)中來實現。
Kubernetes 的職責之一是將“資源”(例如磁碟或容器)放入叢集中並滿足它們所請求的約束。例如:“我必須在可用區 *A* 中”(請參閱 在多個區域中執行),或者“我不能與此 Pod 放置在同一節點上”(請參閱 親和性和反親和性)。
除了這些約束之外,Kubernetes 還提供了 StatefulSet,它為 Pod 提供身份以及“跟隨”這些已識別 Pod 的持久儲存。StatefulSet 中的身份透過 Pod 名稱末尾遞增的整數來處理。需要注意的是,這個整數必須始終是連續的:在一個 StatefulSet 中,如果 Pod 1 和 3 存在,那麼 Pod 2 也必須存在。
在底層,CockroachCloud 將 CockroachDB 的每個區域作為其自己的 Kubernetes 叢集中的 StatefulSet 進行部署——請參閱 在單個 Kubernetes 叢集中編排 CockroachDB。在本文中,我將關注一個獨立的區域、一個 StatefulSet 和一個分佈在至少三個可用區中的 Kubernetes 叢集。
一個三節點的 CockroachCloud 叢集看起來會是這樣
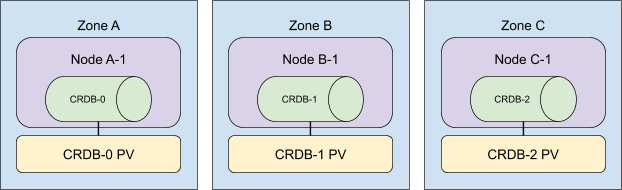
在向叢集新增額外資源時,我們也會將它們分佈到不同的區域。為了獲得最快的使用者體驗,我們同時新增所有 Kubernetes 節點,然後擴充 StatefulSet。
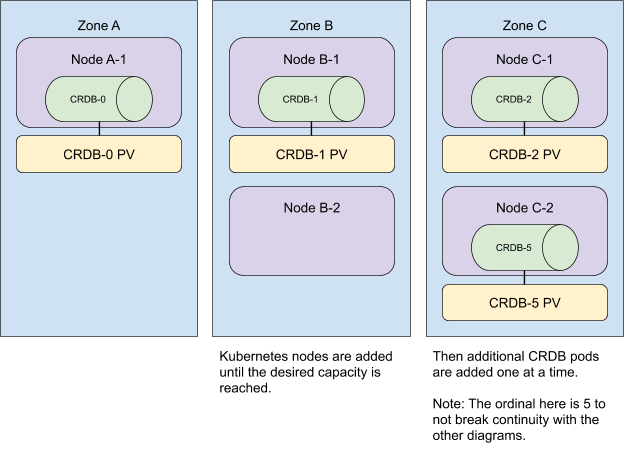
請注意,無論 Pod 分配到 Kubernetes 節點的順序如何,反親和性都會得到滿足。在示例中,Pod 0、1 和 2 分別被分配到區域 A、B 和 C,但 Pod 3 和 4 以不同的順序,分別被分配到區域 B 和 A。反親和性仍然得到滿足,因為這些 Pod 仍然放置在不同的區域中。
要從叢集中移除資源,我們以相反的順序執行這些操作。
我們首先縮減 StatefulSet,然後從叢集中移除所有沒有 CockroachDB Pod 的節點。
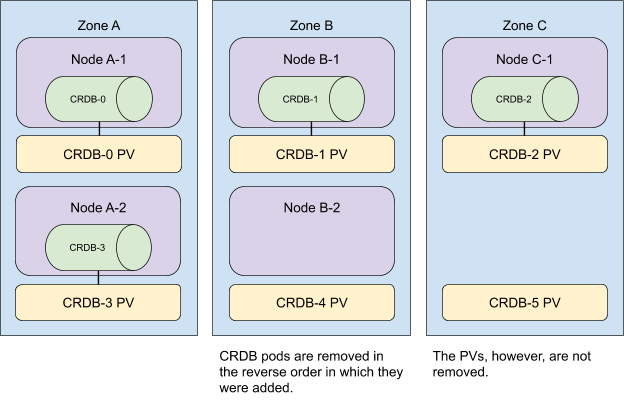
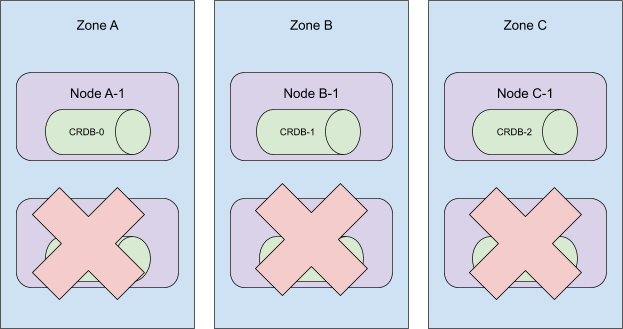
現在,請記住,大小為 *n* 的 StatefulSet 中的 Pod 必須具有範圍 `[0,n)` 內的 ID。當 StatefulSet 縮容 *m* 個 Pod 時,Kubernetes 會從最高序數開始,向最低序數移除 *m* 個 Pod,與它們新增時的順序相反。考慮下面的叢集拓撲
當序數 5 到 3 從此叢集中移除時,StatefulSet 仍會存在於所有 3 個可用區中。
然而,Kubernetes 的排程器並不 *保證* 上述放置,正如我們最初預期的那樣。
我們對以下方面的綜合知識導致了這種誤解。
- Kubernetes 自動將 Pods 分散到不同區域 的能力
- 當 Pod 部署時,一個具有 *n* 個副本的 StatefulSet 會按 ` {0..n-1} ` 的順序依次建立 Pod 的行為。有關更多詳細資訊,請參閱 StatefulSet。
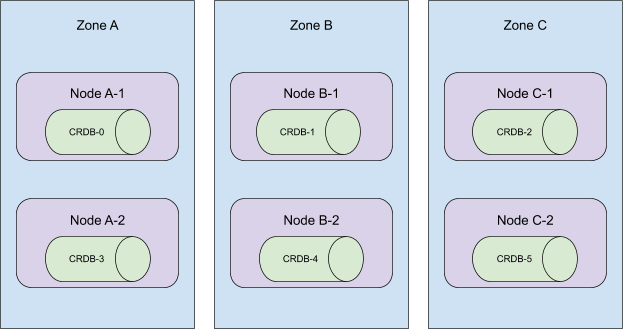
考慮以下拓撲
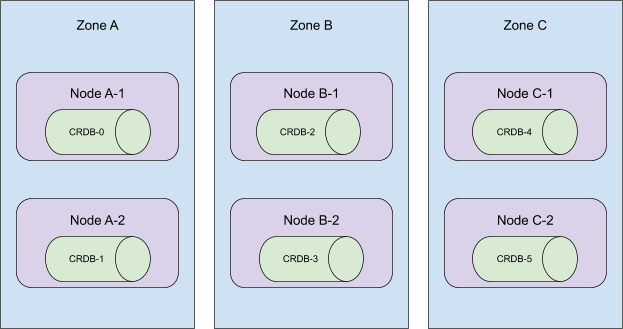
這些 Pod 是按順序建立的,並分佈在叢集的所有可用區中。當序數 5 到 3 被終止時,這個叢集將失去在區域 C 的存在!
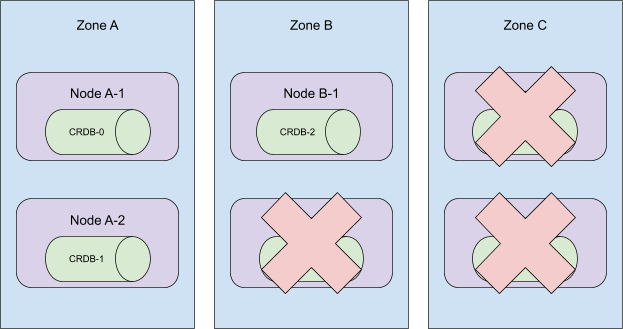
更糟糕的是,當時我們的自動化會移除節點 A-2、B-2 和 C-2。這使得 CRDB-1 處於未排程狀態,因為持久卷只能在其最初建立的區域中使用。
為了糾正後一個問題,我們現在採用“逐個搜尋”的方法來從叢集中移除機器。不再盲目地從叢集中移除 Kubernetes 節點,而是隻移除沒有 CockroachDB Pod 的節點。更艱鉅的任務是駕馭 Kubernetes 排程器。
一次頭腦風暴會議給我們留下了 3 個選擇
1. 升級到 Kubernetes 1.18 並利用 Pod 拓撲散佈約束。
雖然這看起來可能是一個完美的解決方案,但在撰寫本文時,Kubernetes 1.18 在公共雲中最常見的兩個託管 Kubernetes 服務 EKS 和 GKE 上尚不可用。此外,Pod 拓撲散佈約束 在 1.18 中仍然是一個 Beta 功能,這意味著即使 v1.18 可用,它也不保證在託管叢集中可用。整個嘗試令人擔憂地讓人想起在 Internet Explorer 8 仍然存在時檢視 caniuse.com。
2. **按區域部署 StatefulSet。**
與其讓一個 StatefulSet 分佈在所有可用區域,不如為每個區域提供一個具有節點親和性的 StatefulSet,這樣可以手動控制我們的區域拓撲。我們的團隊過去曾將此視為一個選項,這使其特別有吸引力。最終,我們決定放棄此選項,因為它將需要對我們的程式碼庫進行大規模改造,並且對現有客戶叢集進行遷移也將是一項同樣浩大的工程。
3. 編寫一個自定義的 Kubernetes 排程器。
感謝 Kelsey Hightower 的一個例子和 Banzai Cloud 的一篇部落格文章,我們決定深入研究並編寫我們自己的 自定義 Kubernetes 排程器。一旦我們的概念驗證部署並執行,我們很快發現 Kubernetes 排程器還負責將持久卷對映到它排程的 Pod。 kubectl get events 的輸出曾讓我們相信有另一個系統在執行。在尋找負責儲存宣告對映的元件的過程中,我們發現了 kube-scheduler 外掛系統。我們的下一個 POC 是一個 `Filter` 外掛,它根據 Pod 序數確定適當的可用區,並且它完美無缺地工作!
我們的 自定義排程器外掛 是開源的,並在我們所有的 CockroachCloud 叢集中執行。控制 StatefulSet Pods 的排程方式讓我們能夠自信地進行擴充套件。一旦 Pod 拓撲散佈約束在 GKE 和 EKS 中可用,我們可能會考慮淘汰我們的外掛,但維護開銷出人意料地低。更好的是:外掛的實現與我們的業務邏輯正交。部署它或將其淘汰,就像更改 StatefulSet 定義中的 `schedulerName` 欄位一樣簡單。
Chris Seto 是 Cockroach Labs 的軟體工程師,負責 CockroachCloud 和 CockroachDB 的 Kubernetes 自動化。