本文發表於一年多前。舊文章可能包含過時內容。請檢查頁面中的資訊自發布以來是否已變得不正確。
介紹 PodTopologySpread
管理 Pod 在叢集中的分佈是困難的。眾所周知的 Kubernetes Pod 親和性和反親和性功能允許對 Pod 在不同拓撲中的放置進行一些控制。然而,這些功能只解決了 Pod 分佈用例的一部分:要麼將無限數量的 Pod 放置到單個拓撲中,要麼不允許兩個 Pod 共存到同一拓撲中。在這兩個極端情況之間,普遍存在將 Pod 均勻分佈在拓撲中的需求,以實現更好的叢集利用率和應用程式的高可用性。
PodTopologySpread 排程外掛(最初提議為 EvenPodsSpread)旨在彌補這一空白。我們在 1.18 版本中將其提升為 Beta 版。
API 變更
Pod 的 spec API 中引入了一個新欄位 topologySpreadConstraints
spec:
topologySpreadConstraints:
- maxSkew: <integer>
topologyKey: <string>
whenUnsatisfiable: <string>
labelSelector: <object>
由於此 API 嵌入在 Pod 的 spec 中,您可以在所有高階工作負載 API 中使用此功能,例如 Deployment、DaemonSet、StatefulSet 等。
讓我們看一個叢集示例來理解這個 API。
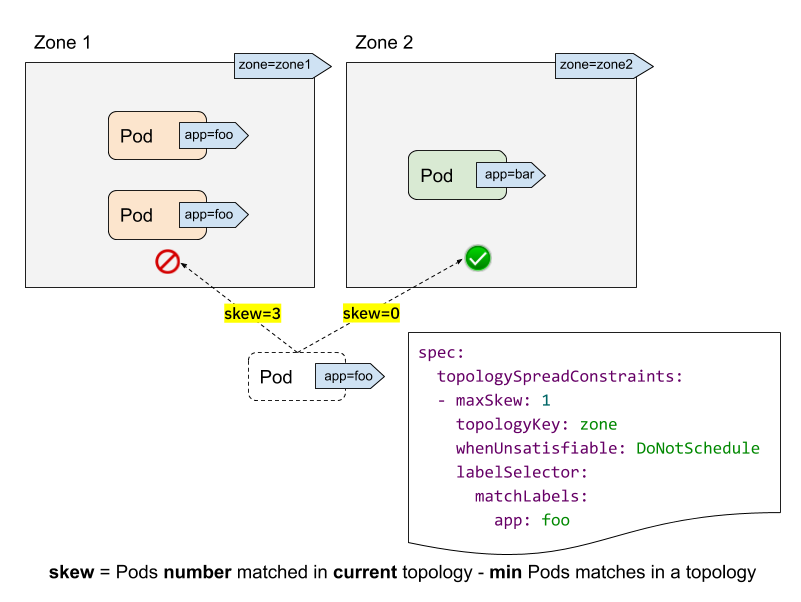
- labelSelector 用於查詢匹配的 Pod。對於每個拓撲,我們計算匹配此標籤選擇器的 Pod 數量。在上面的示例中,給定 labelSelector 為“app: foo”,在“zone1”中匹配的數量為 2;而在“zone2”中為 0。
- topologyKey 是定義節點標籤中拓撲的鍵。在上面的示例中,如果某些節點具有“zone=zone1”標籤,則它們被分組到“zone1”中;而其他節點則被分組到“zone2”中。
- maxSkew 描述 Pod 不均勻分佈的最大程度。在上面的示例中
- 如果我們將傳入的 Pod 放入“zone1”,則“zone1”上的傾斜將變為 3(“zone1”中有 3 個 Pod 匹配;“zone2”中全域性最小值為 0 個 Pod 匹配),這違反了“maxSkew: 1”約束。
- 如果傳入的 Pod 放置到“zone2”,則“zone2”上的傾斜為 0(“zone2”中有 1 個 Pod 匹配;“zone2”中全域性最小值為 1 個 Pod 匹配),這滿足了“maxSkew: 1”約束。請注意,傾斜是按每個合格節點計算的,而不是全域性傾斜。
- whenUnsatisfiable 指定當“maxSkew”無法滿足時應採取的操作
DoNotSchedule(預設)告訴排程器不要排程它。這是一個硬約束。ScheduleAnyway告訴排程器仍然排程它,同時優先考慮減少傾斜的節點。這是一個軟約束。
高階用法
正如功能名稱“PodTopologySpread”所暗示的,此功能的基本用法是以絕對均勻的方式 (maxSkew=1) 或相對均勻的方式 (maxSkew>=2) 執行您的工作負載。有關更多詳細資訊,請參閱官方文件。
除了此基本用法之外,還有一些高階用法示例可以使您的工作負載受益於高可用性和叢集利用率。
與 NodeSelector / NodeAffinity 一起使用
您可能已經發現我們沒有“topologyValues”欄位來限制 Pod 將排程到的拓撲。預設情況下,它會搜尋所有節點並按“topologyKey”將它們分組。有時這可能不是理想情況。例如,假設有一個叢集,其中節點標記為“env=prod”、“env=staging”和“env=qa”,現在您希望將 Pod 均勻地放置到跨區域的“qa”環境中,這可能嗎?
答案是肯定的。您可以利用 NodeSelector 或 NodeAffinity API 規範。在底層,PodTopologySpread 功能將遵循該規範,並在滿足選擇器的節點之間計算傳播約束。
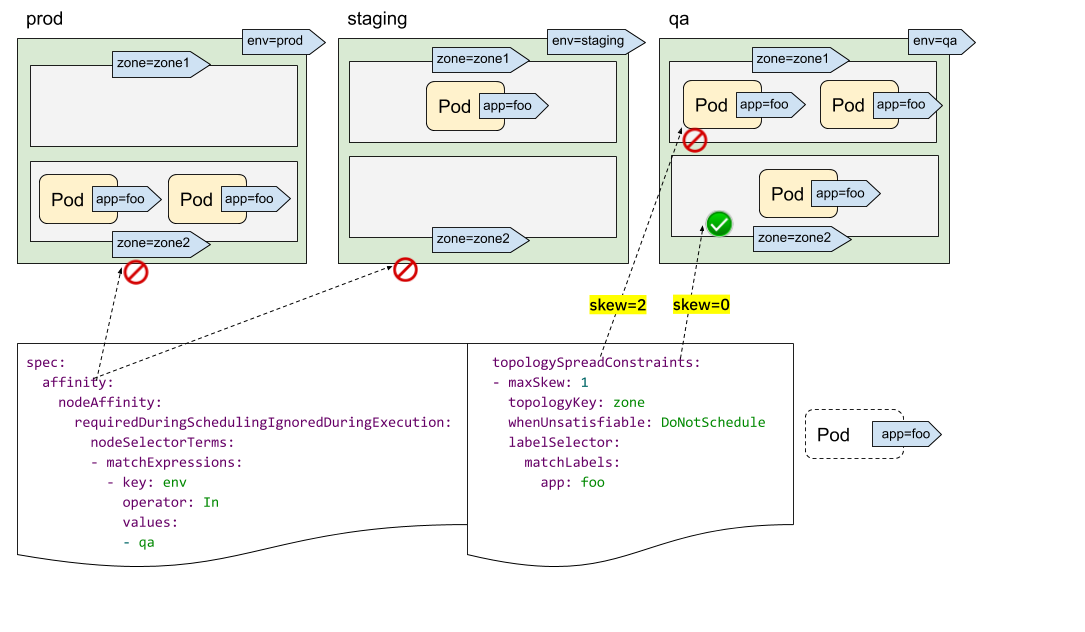
如上圖所示,您可以指定 spec.affinity.nodeAffinity 將“搜尋範圍”限制為“qa”環境,在該範圍內,Pod 將被排程到滿足 topologySpreadConstraints 的區域。在這種情況下,是“zone2”。
多個 TopologySpreadConstraints
直觀地理解單個 TopologySpreadConstraint 的工作原理。那麼多個 TopologySpreadConstraints 的情況如何呢?在內部,每個 TopologySpreadConstraint 都是獨立計算的,結果集將合併以生成最終結果集——即合適的節點。
在以下示例中,我們希望同時將 Pod 排程到具有 2 個要求的叢集中
- 將 Pod 均勻地放置在跨區域的 Pod 中
- 將 Pod 均勻地放置在跨節點的 Pod 中
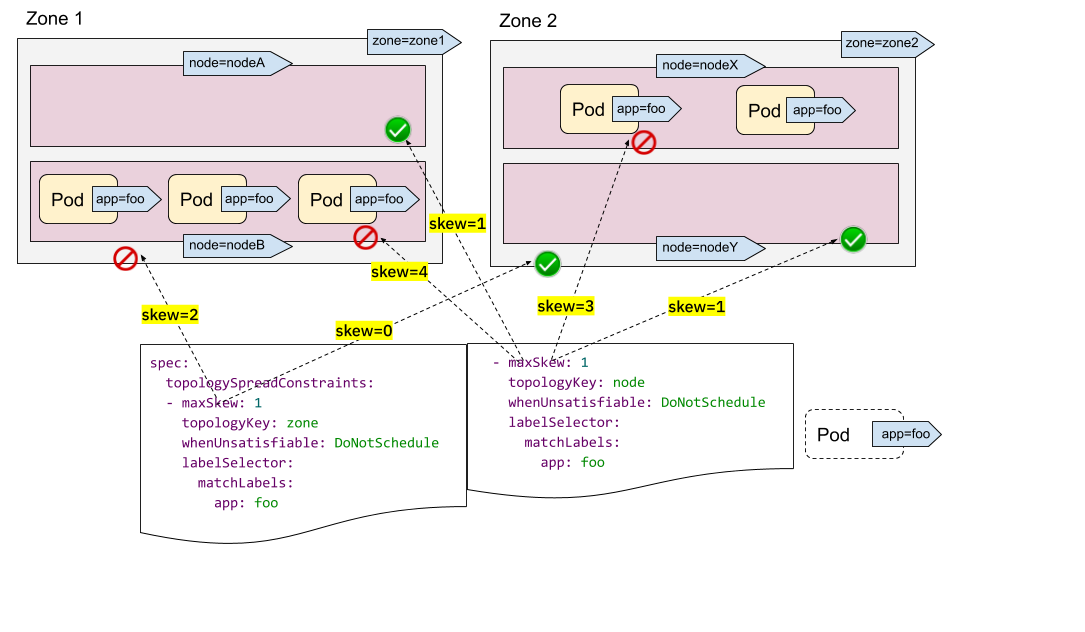
對於第一個約束,zone1 中有 3 個 Pod,zone2 中有 2 個 Pod,因此傳入的 Pod 只能放置到 zone2 以滿足“maxSkew=1”約束。換句話說,結果集是 nodeX 和 nodeY。
對於第二個約束,nodeB 和 nodeX 中有太多 Pod,因此傳入的 Pod 只能放置到 nodeA 和 nodeY。
現在我們可以得出結論,唯一合格的節點是 nodeY——來自集合 {nodeX, nodeY}(來自第一個約束)和 {nodeA, nodeY}(來自第二個約束)的交集。
多個 TopologySpreadConstraints 功能強大,但請務必理解與前面“NodeSelector/NodeAffinity”示例的區別:一個是獨立計算結果集然後合併;另一個是基於節點約束的過濾結果計算 topologySpreadConstraints。
除了在所有 topologySpreadConstraints 中使用“硬”約束之外,您還可以結合使用“硬”約束和“軟”約束,以適應更多樣化的叢集情況。
說明
如果對相同的 {topologyKey, whenUnsatisfiable} 元組應用了兩個 TopologySpreadConstraints,則 Pod 建立將被阻止並返回驗證錯誤。PodTopologySpread 預設值
PodTopologySpread 是一個 Pod 級別的 API。因此,要使用此功能,工作負載作者需要了解叢集的底層拓撲,然後在每個工作負載的 Pod 規範中指定適當的 topologySpreadConstraints。雖然 Pod 級別的 API 提供了最大的靈活性,但也可以指定叢集級別的預設值。
預設的 PodTopologySpread 約束允許您為叢集中的所有工作負載指定傳播,並根據其拓撲進行定製。這些約束可以由操作員/管理員在啟動 kube-scheduler 時在排程配置檔案配置 API 中指定為 PodTopologySpread 外掛引數。
一個示例配置可能如下所示
apiVersion: kubescheduler.config.k8s.io/v1alpha2
kind: KubeSchedulerConfiguration
profiles:
pluginConfig:
- name: PodTopologySpread
args:
defaultConstraints:
- maxSkew: 1
topologyKey: example.com/rack
whenUnsatisfiable: ScheduleAnyway
配置預設約束時,標籤選擇器必須留空。kube-scheduler 將根據 Pod 與 Services、ReplicationControllers、ReplicaSets 或 StatefulSets 的隸屬關係推斷標籤選擇器。Pod 始終可以透過在 PodSpec 中提供自己的約束來覆蓋預設約束。
說明
使用預設 PodTopologySpread 約束時,建議停用舊的 DefaultTopologySpread 外掛。總結
PodTopologySpread 允許您使用靈活且富有表現力的 Pod 級 API 為工作負載定義傳播約束。過去,工作負載作者使用 Pod 反親和性規則來強制或提示排程器在每個拓撲域中執行單個 Pod。相比之下,新的 PodTopologySpread 約束允許 Pod 指定傾斜級別,這些級別可以是必需的(硬約束)或期望的(軟約束)。該功能可以與節點選擇器和節點親和性配對使用,以將傳播限制到特定域。Pod 傳播約束可以為不同的拓撲(例如主機名、區域、區域、機架等)定義。
最後,叢集操作員可以定義要應用於所有 Pod 的預設約束。這樣,Pod 就不需要了解叢集的底層拓撲。