本文發表於一年多前。舊文章可能包含過時內容。請檢查頁面中的資訊自發布以來是否已變得不正確。
宣佈 etcd 3.4
etcd 3.4 版本重點關注穩定性、效能和易操作性,引入了預投票和非投票成員等功能,並改進了儲存後端和客戶端負載均衡器。
有關完整的更改列表,請參閱更新日誌。
更好的儲存後端
etcd v3.4 包含了許多針對大規模 Kubernetes 工作負載的效能改進。
特別是,etcd 在大量併發讀取事務時(即使沒有寫入操作,例如 “read-only range request ... took too long to execute”)也會出現效能問題。以前,儲存後端對掛起寫入的提交操作會阻塞傳入的讀取事務,即使沒有掛起寫入。現在,提交不再阻塞讀取,從而改善了長時間執行的讀取事務效能。
我們進一步使後端讀取事務完全併發。以前,正在進行的長時間執行的讀取事務會阻塞寫入和即將進行的讀取。透過此更改,在長時間執行的讀取存在的情況下,寫入吞吐量增加了 70%,P99 寫入延遲降低了 90%。我們還在 GCE 上使用此更改運行了Kubernetes 5000 節點可伸縮性測試,並觀察到類似的改進。例如,在測試開始時,存在大量長時間執行的“LIST pods”,P99 “POST clusterrolebindings”的延遲降低了 97.4%。
租約儲存也得到了更多改進。我們透過更有效地儲存租約物件,增強了租約過期/撤銷效能,並使租約查詢操作非阻塞,與當前的租約授予/撤銷操作併發執行。etcd v3.4 還引入了租約檢查點作為一項實驗性功能,透過共識持久化剩餘的生存時間值。這確保了短壽命租約物件在領導選舉後不會自動續訂。這也防止了當生存時間值相對較大時(例如,Kubernetes 用例中 1 小時 TTL 永不過期)租約物件堆積。
改進的 Raft 投票過程
etcd 伺服器實現了Raft 共識演算法用於資料複製。Raft 是一種基於領導者的協議。資料從領導者複製到追隨者;追隨者將提議轉發給領導者,領導者決定是否提交。領導者持久化並複製一個條目,一旦它得到叢集法定人數的同意。叢集成員選舉一個單一的領導者,所有其他成員都成為追隨者。當選的領導者定期向其追隨者傳送心跳以維持其領導地位,並期望從每個追隨者那裡得到響應以跟蹤其進度。
在最簡單的形式中,當 Raft 領導者收到帶有更高任期的訊息時,它會退位成為追隨者,而無需進行任何進一步的叢集範圍健康檢查。這種行為可能會影響整個叢集的可用性。
例如,一個不穩定的(或重新加入的)成員反覆進出,並開始競選。這個成員最終會擁有更高的任期,忽略所有帶有更低任期的傳入訊息,併發送帶有更高任期的訊息。當領導者收到這條更高任期的訊息時,它會退回到追隨者狀態。
當出現網路分割槽時,這會變得更具破壞性。每當分割槽節點恢復連線時,它可能會觸發領導者重新選舉。為了解決這個問題,etcd Raft 引入了一個新的節點狀態“預候選者”,並具有預投票功能。預候選者首先詢問其他伺服器,它是否足夠最新以獲得投票。只有當它能獲得多數投票時,它才會增加其任期並開始選舉。這個額外的階段通常會提高領導者選舉的魯棒性。並且只要領導者與其法定人數的對等體保持連線,它就能保持穩定。
同樣,當重啟的節點沒有及時收到領導者心跳(例如由於網路緩慢)時,etcd 的可用性可能會受到影響,這會觸發領導者選舉。以前,etcd 在伺服器啟動時會快進選舉計時,只剩下一次計時用於領導者選舉。例如,當選舉超時為 1 秒時,追隨者只等待 100 毫秒的領導者聯絡,然後才開始選舉。這加快了初始伺服器啟動速度,因為無需等待選舉超時(例如,在 100 毫秒而不是 1 秒內觸發選舉)。推進選舉計時對於具有更大選舉超時的跨資料中心部署也很有用。然而,在許多情況下,可用性比初始領導者選舉的速度更關鍵。為了確保重新加入節點的更好可用性,etcd 現在調整選舉計時,保留多於一次計時,從而為領導者提供更多時間來防止破壞性重啟。
Raft 非投票成員,學習者
成員資格重新配置的挑戰在於它通常會導致法定人數大小的變化,這容易導致叢集不可用。即使它不改變法定人數,成員資格發生變化的叢集也更有可能遇到其他潛在問題。為了提高重新配置的可靠性和信心,etcd 3.4 版本引入了一個新角色——學習者。
新的 etcd 成員以無初始資料加入叢集,請求領導者所有歷史更新,直到它趕上領導者的日誌。這意味著領導者的網路更容易過載,阻塞或丟棄發給追隨者的領導者心跳。在這種情況下,追隨者可能會遇到選舉超時並開始新的領導者選舉。也就是說,擁有新成員的叢集更容易受到領導者選舉的影響。領導者選舉和隨後對新成員的更新傳播都容易導致叢集不可用期間(參見 圖 1)。
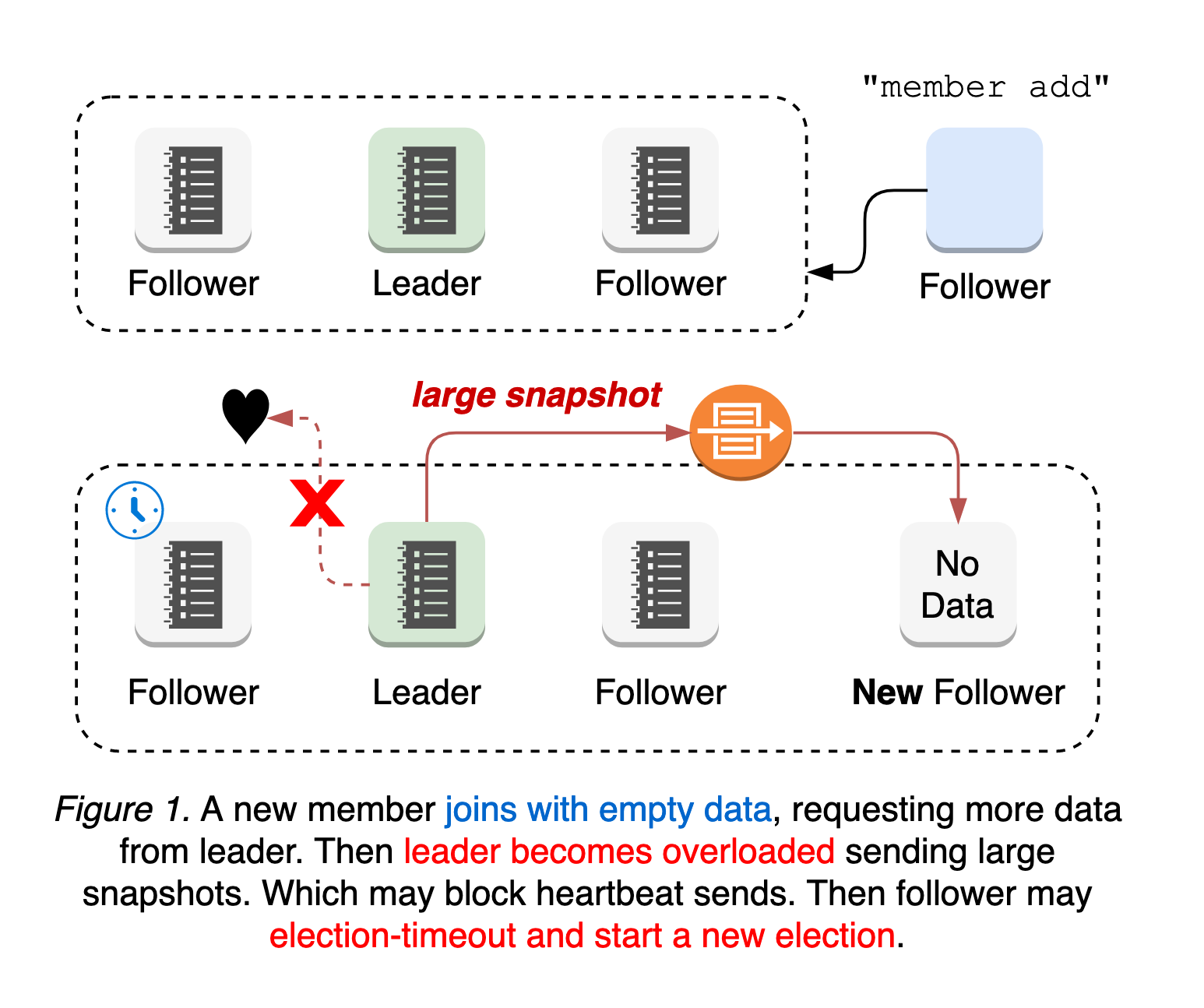
最糟糕的情況是成員新增配置錯誤。etcd 中的成員重配置是一個兩步過程:使用對等 URL 執行 `etcdctl member add` 命令,然後啟動新的 etcd 加入叢集。也就是說,無論對等 URL 值是否無效,`member add` 命令都會被應用。如果第一步是應用無效的 URL 並改變法定人數大小,則叢集在新的節點連線之前就可能失去法定人數。由於具有無效 URL 的節點永遠不會上線且沒有領導者,因此無法回滾成員更改(參見 圖 2)。
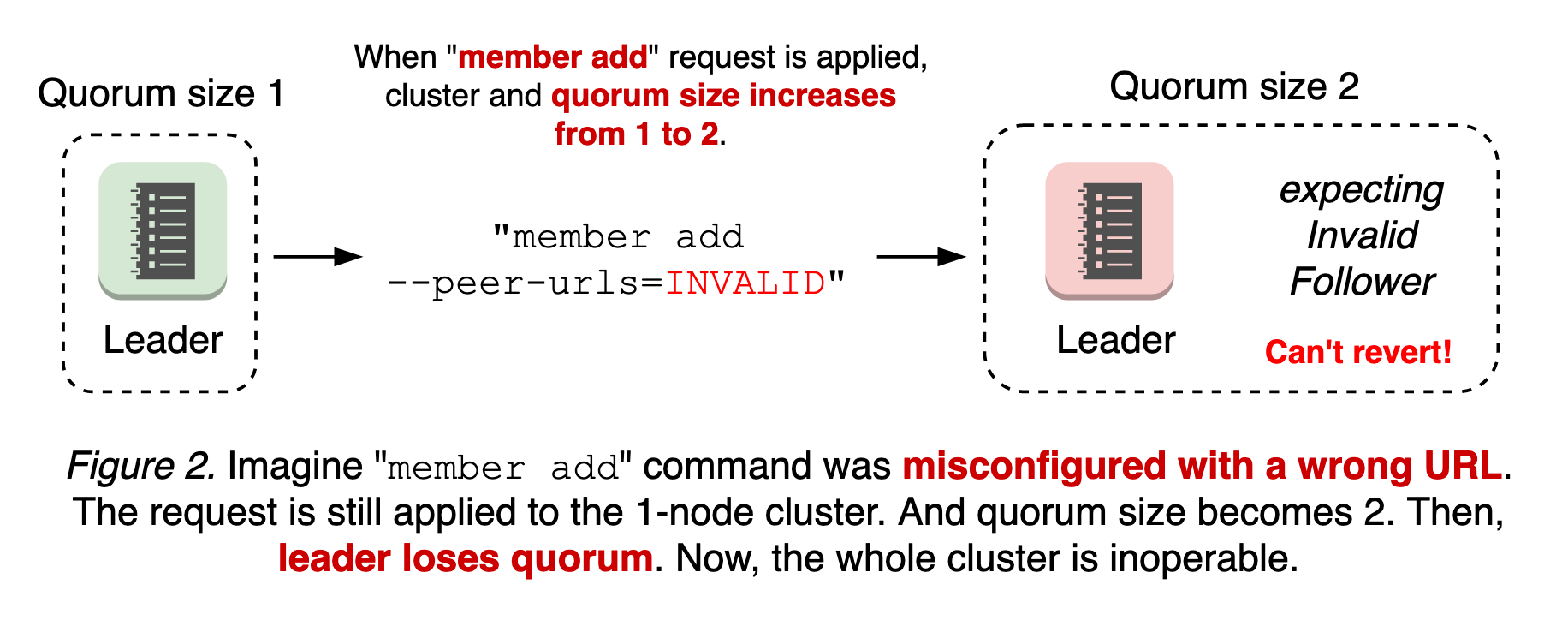
當存在分割槽節點時,情況會變得更加複雜(有關更多資訊,請參閱設計文件)。
為了解決這些故障模式,etcd 引入了一個新的節點狀態“學習者”,它以非投票成員的身份加入叢集,直到它趕上領導者的日誌。這意味著學習者仍然接收領導者的所有更新,但它不計入法定人數,法定人數由領導者用於評估對等體的活躍性。學習者在晉升之前只充當備用節點。這種對法定人數的寬鬆要求在成員重配置和操作安全性期間提供了更好的可用性(參見 圖 3)。
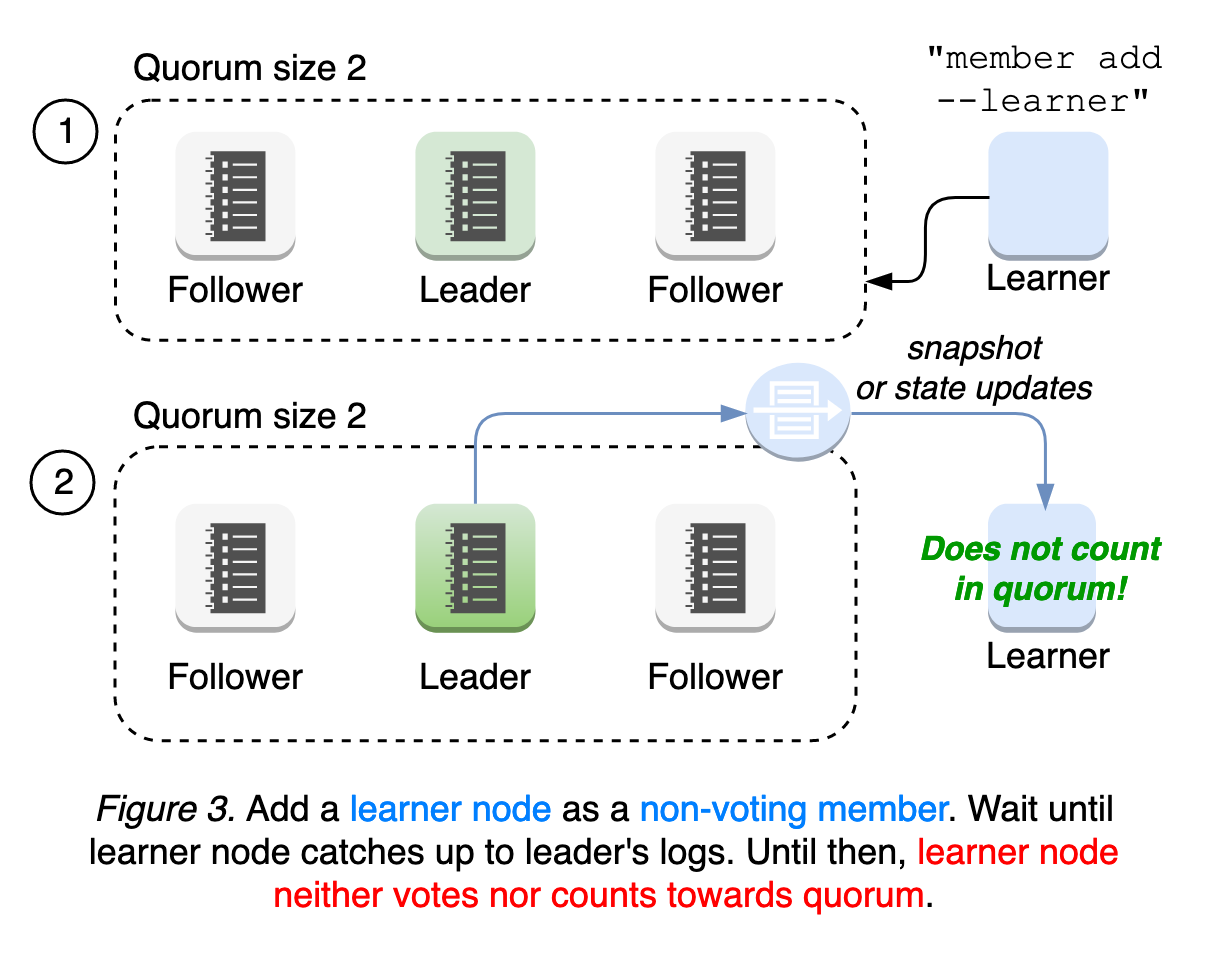
我們將進一步提高學習者的魯棒性,並探索自動晉升機制,以實現更簡單、更可靠的操作。請閱讀我們的學習者設計文件和執行時配置文件以獲取使用者指南。
新的客戶端負載均衡器
etcd 旨在容忍各種系統和網路故障。按照設計,即使一個節點宕機,叢集也能“看似”正常工作,因為它提供了多臺伺服器的統一邏輯叢集檢視。但是,這並不能保證客戶端的活性。因此,etcd 客戶端實現了一套不同的複雜協議,以保證其在故障條件下的正確性和高可用性。
從歷史上看,etcd 客戶端負載均衡器嚴重依賴舊的 gRPC 介面:每次 gRPC 依賴項升級都會破壞客戶端行為。大量的開發和除錯工作都致力於修復這些客戶端行為變更。結果,其實現變得過於複雜,對伺服器連線做出了錯誤的假設。主要目標是簡化 etcd v3.4 客戶端中的負載均衡器故障轉移邏輯;不再維護可能過時的不健康端點列表,而是在客戶端與當前端點斷開連線時,簡單地輪詢到下一個端點。它不假定端點狀態。因此,不再需要複雜的狀跟蹤。
此外,新的客戶端現在會建立自己的憑據捆綁包,以修復針對安全端點的負載均衡器故障轉移。這解決了長達一年的 bug,即當第一個 etcd 伺服器不可用時,kube-apiserver 會失去與 etcd 叢集的連線。
有關更多資訊,請參閱客戶端負載均衡器設計文件。