本文發表於一年多前。舊文章可能包含過時內容。請檢查頁面中的資訊自發布以來是否已變得不正確。
kube-proxy 的細微之處:除錯間歇性連線重置
最近我遇到了一個導致間歇性連線重置的 Bug。經過一番深入研究,我發現它是由幾個不同的網路子系統的微妙組合引起的。這幫助我更好地理解了 Kubernetes 網路,我認為這值得與對同一主題感興趣的更廣泛受眾分享。
症狀
我們收到了一份使用者報告,聲稱他們在同一個叢集中使用 ClusterIP 型別的 Kubernetes 服務向執行在 Pod 中的大型檔案提供服務時,遇到了連線重置。初步除錯叢集並沒有發現任何有趣的問題:網路連線正常,下載檔案也沒有遇到任何問題。然而,當我們並行執行許多客戶端的工作負載時,我們能夠重現該問題。更神秘的是,當在沒有 Kubernetes 的虛擬機器上執行工作負載時,該問題無法重現。這個問題可以很容易地透過一個簡單的應用程式重現,顯然與 Kubernetes 網路有關,但這到底是什麼原因呢?
Kubernetes 網路基礎
在深入研究這個問題之前,讓我們先談談 Kubernetes 網路的一些基礎知識,因為 Kubernetes 處理來自 Pod 的網路流量的方式,會根據不同的目的地而大相徑庭。
Pod 到 Pod
在 Kubernetes 中,每個 Pod 都有自己的 IP 地址。好處是,執行在 Pod 內部的應用程式可以使用其規範埠,而無需重新對映到不同的隨機埠。Pod 之間具有 L3 連線。它們可以互相 ping,並互相傳送 TCP 或 UDP 資料包。CNI 是解決不同主機上執行的容器之間此問題的標準。有大量的不同外掛支援 CNI。
Pod 到外部
對於從 Pod 到外部地址的流量,Kubernetes 簡單地使用 SNAT。它所做的是用主機的 IP:埠替換 Pod 的內部源 IP:埠。當返回的資料包回到主機時,它將 Pod 的 IP:埠重寫為目的地,並將其傳送回原始 Pod。整個過程對原始 Pod 是透明的,它完全不知道地址轉換。
Pod 到服務
Pod 是短暫的。大多數情況下,人們希望獲得可靠的服務。否則,它幾乎毫無用處。因此,Kubernetes 有一個叫做“服務”的概念,它只是 Pod 前面的 L4 負載均衡器。服務有幾種不同的型別。最基本的一種叫做 ClusterIP。對於這種型別的服務,它有一個唯一的 VIP 地址,只能在叢集內部路由。
Kubernetes 中實現此功能的元件稱為 kube-proxy。它位於每個節點上,並程式設計複雜的 iptables 規則以執行 Pod 和服務之間的各種過濾和 NAT。如果您進入 Kubernetes 節點並鍵入 iptables-save,您將看到 Kubernetes 或其他程式插入的規則。最重要的鏈是 KUBE-SERVICES、KUBE-SVC-* 和 KUBE-SEP-*。
KUBE-SERVICES是服務資料包的入口點。它的作用是匹配目標 IP:埠並將資料包分派到相應的KUBE-SVC-*鏈。KUBE-SVC-*鏈充當負載均衡器,並將資料包平均分配到KUBE-SEP-*鏈。每個KUBE-SVC-*具有與其後面的端點數量相同的KUBE-SEP-*鏈數。KUBE-SEP-*鏈代表一個服務端點。它簡單地執行 DNAT,用 Pod 的端點 IP:埠替換服務 IP:埠。
對於 DNAT,conntrack 會介入並使用狀態機跟蹤連線狀態。需要狀態是因為它需要記住它更改到的目標地址,並在返回資料包回來時將其更改回來。Iptables 也可以依靠 conntrack 狀態(ctstate)來決定資料包的命運。這 4 種 conntrack 狀態尤其重要:
- NEW:conntrack 對此資料包一無所知,這發生在收到 SYN 資料包時。
- ESTABLISHED:conntrack 知道資料包屬於已建立的連線,這發生在握手完成後。
- RELATED:資料包不屬於任何連線,但它與另一個連線相關聯,這對於 FTP 等協議特別有用。
- INVALID:資料包有問題,conntrack 不知道如何處理它。此狀態在此 Kubernetes 問題中起著核心作用。
以下是 Pod 與服務之間 TCP 連線如何工作的圖示。事件序列如下:
- 左側客戶端 Pod 向服務傳送資料包:192.168.0.2:80
- 資料包透過客戶端節點中的 iptables 規則,目的地更改為 Pod IP,即 10.0.1.2:80
- 伺服器 Pod 處理資料包併發送回目標為 10.0.0.2 的資料包
- 資料包返回到客戶端節點,conntrack 識別資料包並將源地址重寫回 192.169.0.2:80
- 客戶端 Pod 收到響應資料包
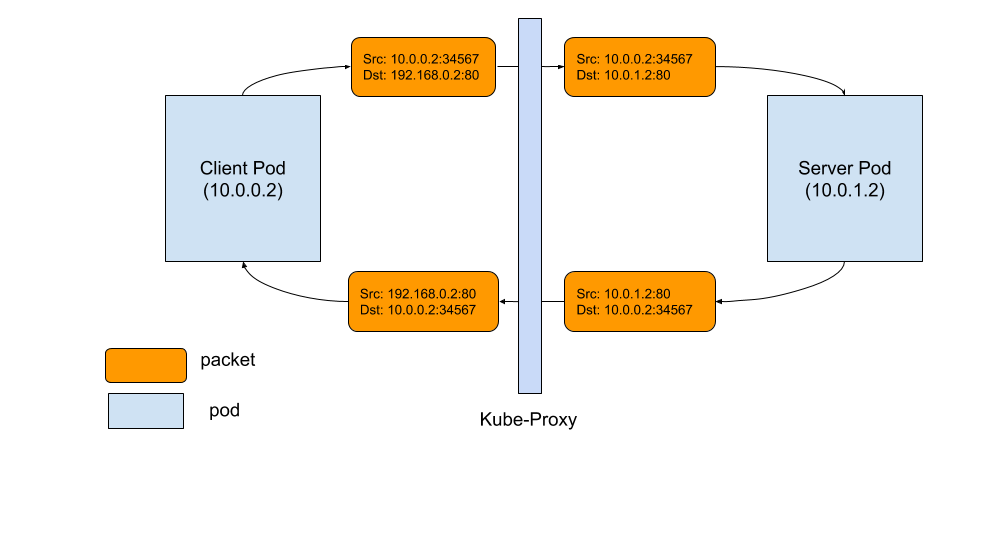
良好資料包流
什麼導致了連線重置?
背景知識已經足夠了,那麼究竟是什麼地方出了問題,導致了意外的連線重置呢?
如下圖所示,問題出在資料包 3。當 conntrack 無法識別返回資料包並將其標記為 INVALID 時。最常見的原因包括:conntrack 因容量不足而無法跟蹤連線,資料包本身超出 TCP 視窗等。對於那些被 conntrack 標記為 INVALID 狀態的資料包,我們沒有 iptables 規則來丟棄它,因此它將被轉發到客戶端 Pod,其源 IP 地址未被重寫(如資料包 4 所示)!客戶端 Pod 不識別此資料包,因為它具有不同的源 IP,即 Pod IP,而不是服務 IP。結果,客戶端 Pod 會說:“等一下,我不記得曾經與這個 IP 建立過連線,為什麼這傢伙一直給我傳送這個資料包?”基本上,客戶端所做的就是簡單地向伺服器 Pod IP 傳送一個 RST 資料包,這就是資料包 5。不幸的是,這是一個完全合法的 Pod-to-Pod 資料包,可以傳遞到伺服器 Pod。伺服器 Pod 不知道客戶端發生的所有地址轉換。從它的角度來看,資料包 5 是一個完全合法的資料包,就像資料包 2 和 3。伺服器 Pod 所知道的只是,“好吧,客戶端 Pod 不想和我說話,所以我們關閉連線吧!”轟!當然,為了使這一切發生,RST 資料包也必須是合法的,具有正確的 TCP 序列號等。但當它發生時,雙方都同意關閉連線。
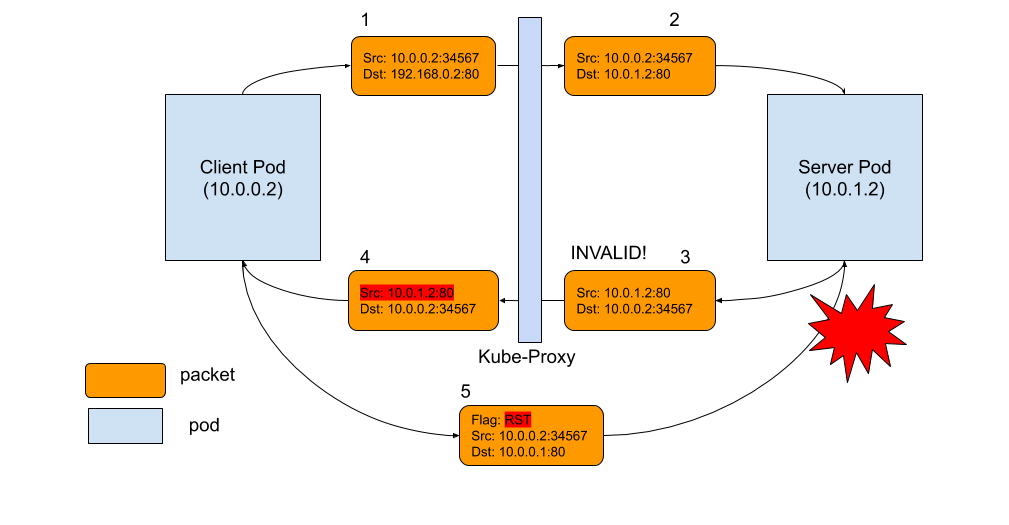
連線重置資料包流
如何解決?
一旦我們理解了根本原因,修復就不難了。至少有兩種方法可以解決它。
- 讓 conntrack 對資料包更寬鬆,不要將資料包標記為 INVALID。在 Linux 中,您可以透過
echo 1 > /proc/sys/net/ipv4/netfilter/ip_conntrack_tcp_be_liberal來實現。 - 專門新增 iptables 規則以丟棄標記為 INVALID 的資料包,這樣它就不會到達客戶端 Pod 並造成損害。
此修復已在 v1.15+ 中提供。但是,對於受此 Bug 影響的使用者,可以透過在叢集中應用以下規則來緩解問題。
apiVersion: extensions/v1beta1
kind: DaemonSet
metadata:
name: startup-script
labels:
app: startup-script
spec:
template:
metadata:
labels:
app: startup-script
spec:
hostPID: true
containers:
- name: startup-script
image: gcr.io/google-containers/startup-script:v1
imagePullPolicy: IfNotPresent
securityContext:
privileged: true
env:
- name: STARTUP_SCRIPT
value: |
#! /bin/bash
echo 1 > /proc/sys/net/ipv4/netfilter/ip_conntrack_tcp_be_liberal
echo done
總結
顯然,這個 Bug 幾乎一直存在。我很驚訝直到最近才被注意到。我認為原因可能是:(1)這種情況更多地發生在擁擠的伺服器上,處理大負載,這可能不是一個常見的用例;(2)應用程式層處理重試以容忍這種重置。無論如何,無論 Kubernetes 增長多快,它仍然是一個年輕的專案。除了密切傾聽客戶反饋,不把任何事情視為理所當然並深入挖掘,沒有其他秘密能使其成為執行應用程式的最佳平臺。