本文發表於一年多前。舊文章可能包含過時內容。請檢查頁面中的資訊自發布以來是否已變得不正確。
Poseidon-Firmament 排程器——基於流網路圖的排程器
引言
在雲規模資料中心環境(也稱為“**資料中心即計算機**”或“**倉庫規模計算 - WSC**”)中,Mesos、Google Borg、Kubernetes 等叢集管理系統通常透過執行跟蹤機器活躍度、啟動、監控、終止工作負載等任務來管理應用程式工作負載,更重要的是,使用**叢集排程器**來決定工作負載的放置。
**叢集排程器**主要負責將工作負載排程到計算資源——結合WSC環境中工作的全域性放置,可以使“倉庫規模計算機”更高效,提高利用率,並節省能源。**叢集排程器**的例子有 Google Borg、Kubernetes、Firmament、Mesos、Tarcil、Quasar、Quincy、Swarm、YARN、Nomad、Sparrow、Apollo 等。
在這篇部落格文章中,我們簡要描述了 Kubernetes 中新穎的 Firmament 流網路圖排程方法(OSDI 論文)。我們特別描述了 Firmament 排程器以及它如何使用 Poseidon 作為整合膠水與 Kubernetes 叢集管理器整合。我們已經看到了這種新穎排程方法在排程吞吐量效能基準測試中令人印象深刻的數字。最初,Firmament 排程器由劍橋大學的研究人員 Malte Schwarzkopf 和 Ionel Gog 構思、設計和實現。
Poseidon-Firmament 排程器 – 工作原理
從高層次看,Poseidon-Firmament 排程器透過將新穎的基於流網路圖的排程功能與預設的 Kubernetes 排程器結合,增強了當前的 Kubernetes 排程能力。它將排程問題建模為流網路圖上的基於約束的最佳化問題,透過將排程簡化為最小成本最大流量最佳化問題。由於其固有的重新排程能力,新的排程器能夠實現一個全域性最優的排程環境,持續動態地最佳化工作負載的放置。
主要優勢
基於流圖排程的 Poseidon-Firmament 排程器提供以下主要優勢:
工作負載(Pod)批次排程,以實現大規模排程決策。
根據廣泛的效能測試結果,隨著叢集中節點數量的增加,Poseidon-Firmament 的擴充套件性遠優於 Kubernetes 預設排程器。這是因為 Poseidon-Firmament 能夠將越來越多的工作分攤到不同的工作負載中。
在計算資源需求在作業(Replicasets/Deployments/Jobs)中相對均勻的場景下,Poseidon-Firmament 排程器在吞吐量效能方面大大優於 Kubernetes 預設排程器。Poseidon-Firmament 排程器的端到端吞吐量效能(包括繫結時間)隨著叢集中節點數量的增加而持續提高。例如,對於一個 2,700 節點的叢集(如此處的圖所示),Poseidon-Firmament 排程器實現了比 Kubernetes 預設排程器高 7 倍或更高的端到端吞吐量,其中包括繫結時間。
支援複雜的規則約束。
Poseidon-Firmament 中的排程非常動態;它在每次排程執行時都使叢集資源保持全域性最優狀態。
高效的資源利用。
Firmament 流網路圖 – 概述
Firmament 排程器在流網路上執行最小成本流演算法,以找到最優流,並從中提取隱含的工作負載(Pod 放置)。流網路是一個有向圖,其弧從源節點(即 Pod 節點)將流傳輸到匯節點。每個弧關聯的成本和容量限制了流,並指定了其優先路徑。
圖 1 顯示了一個流網路示例,其中包含兩個任務(工作負載或 Pod)和四臺機器(節點)——左側的每個工作負載都是一個單位流的源。所有這些流都必須流入匯節點(S),才能獲得最佳化問題的可行解。
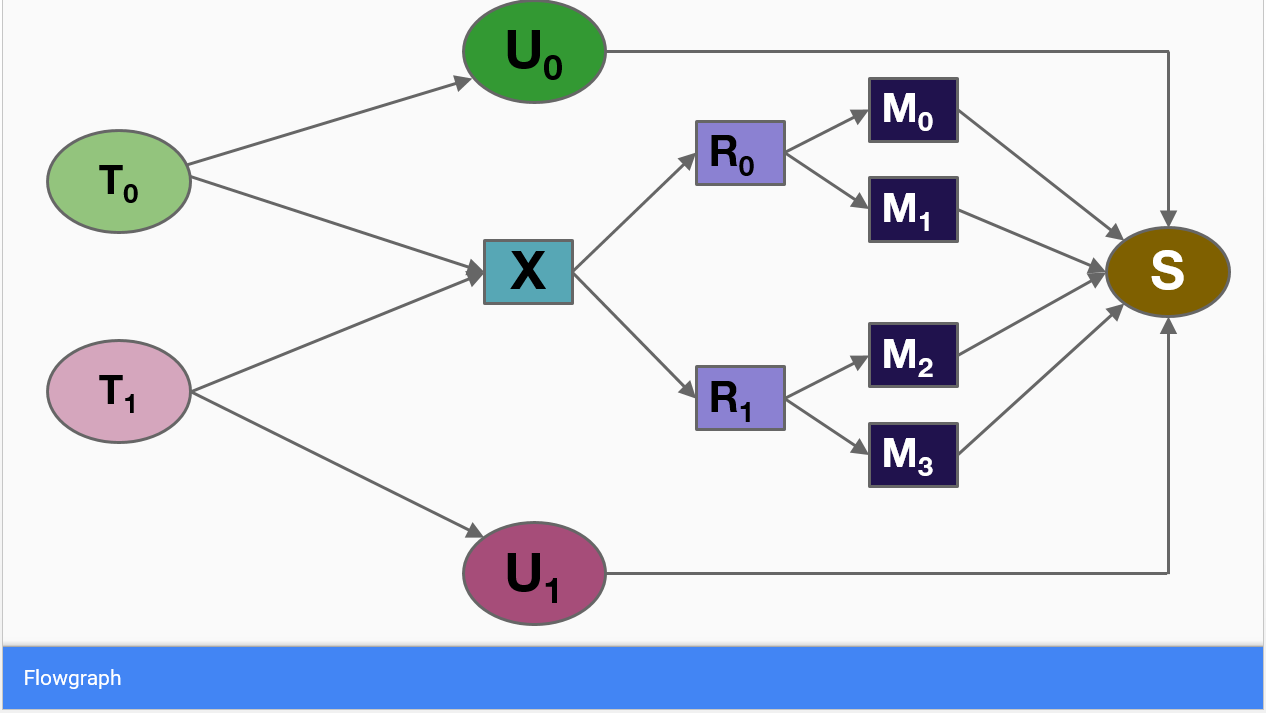
圖 1. 流網路示例
Poseidon 中間層 – 概述
Poseidon 是一種服務,充當 Firmament 排程器與 Kubernetes 整合的連線層。它透過將新的基於流網路圖的 Firmament 排程功能與預設的 Kubernetes 排程器結合,增強了當前的 Kubernetes 排程能力;多個排程器同時執行。圖 2 描述了 Poseidon 整合層如何與底層基於 Firmament 流網路圖的排程器協同工作的高階整體設計。
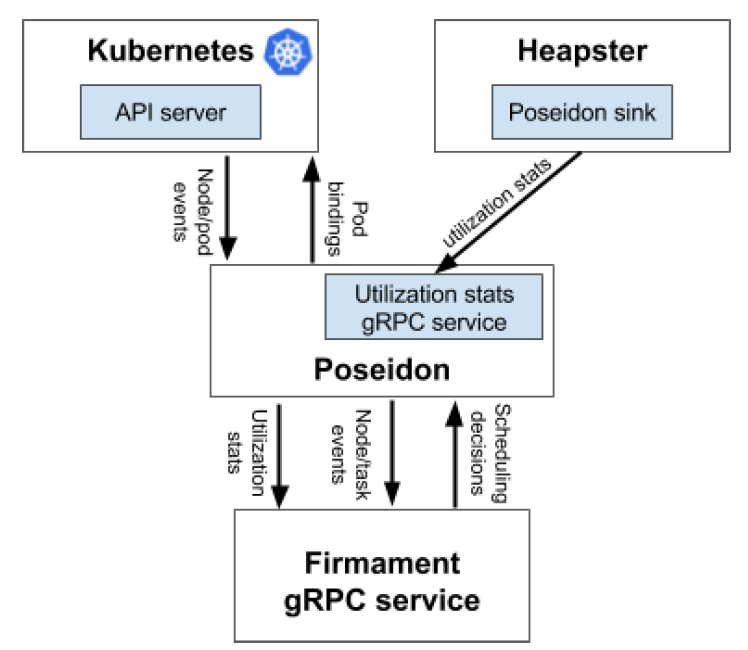
圖 2. Firmament Kubernetes 整合概述
作為 Kubernetes 多排程器支援的一部分,每個新的 Pod 通常由預設排程器排程,但 Kubernetes 可以透過在 Pod 部署時指定另一個自定義排程器(在我們的案例中是 Poseidon-Firmament)的名稱來指示使用該排程器。在這種情況下,預設排程器將忽略該 Pod,並允許 Poseidon 排程器將 Pod 排程到相關節點。
說明
有關該專案設計的詳細資訊,請參閱設計文件。可能的用例場景 – 何時使用它
Poseidon-Firmament 排程器由於其批次排程方法相對於 K8s 的逐個 Pod 排程方法具有優越性,因此能夠在大規模環境下實現極高的吞吐量排程。在我們的廣泛測試中,只要傳入 Pod 的資源需求(CPU/記憶體)在作業(Replicasets/Deployments/Jobs)之間是均勻的,我們就會觀察到顯著的吞吐量優勢,這主要歸因於作業之間工作的有效分攤。
儘管 Poseidon-Firmament 排程器能夠排程各種型別的工作負載(服務、批處理等),但以下是一些它表現最佳的用例:
對於包含大量任務的“大資料/人工智慧”作業,吞吐量優勢巨大。
對於工作負載資源需求在作業(Replicasets/Deplyments/Jobs)中均勻的服務或批處理作業場景,也具有顯著的吞吐量優勢。
當前專案階段
目前 Poseidon-Firmament 專案是一個孵化專案。Alpha 版本可在 https://github.com/kubernetes-sigs/poseidon 獲取。