本文發表於一年多前。舊文章可能包含過時內容。請檢查頁面中的資訊自發布以來是否已變得不正確。
Gardener - Kubernetes 植物學家
如今,Kubernetes 已成為在雲中執行軟體的自然選擇。越來越多的開發人員和公司正在將其應用程式容器化,其中許多正在採用 Kubernetes 來自動化部署其雲原生工作負載。
有許多開源工具可以幫助建立和更新單個 Kubernetes 叢集。然而,您需要的叢集越多,操作、監控、管理以及保持所有叢集處於活動狀態並保持最新狀態就越困難。
這正是“Gardener”專案所關注的。它不僅僅是另一個配置工具,而是旨在將 Kubernetes 叢集作為服務進行管理。它在各種雲提供商上提供符合 Kubernetes 標準的叢集,並能夠大規模維護數百或數千個叢集。在 SAP,我們不僅在自己的平臺中面臨這種異構多雲和本地挑戰,而且在所有實施 Kubernetes 和雲原生的或大或小的客戶那裡也遇到了同樣的需求。
受 Kubernetes 可能性和自託管能力的啟發,Gardener 的基礎是 Kubernetes 本身。雖然自託管(即在 Kubernetes 內部執行 Kubernetes 元件)在社群中是一個熱門話題,但我們應用了一種特殊的模式,以最小的總擁有成本來操作大量叢集。我們使用一個初始的 Kubernetes 叢集(稱為“種子”叢集),並將終端使用者叢集的控制平面元件(如 API 伺服器、排程器、控制器管理器、etcd 等)作為簡單的 Kubernetes pod 播種。本質上,種子叢集的重點是提供大規模的強大控制平面即服務。根據我們的植物學術語,準備發芽的終端使用者叢集被稱為“芽”叢集。考慮到網路延遲和其他故障場景,我們建議每個雲提供商和區域使用一個種子叢集來託管許多芽叢集的控制平面。
總的來說,這種重用 Kubernetes 原語的概念已經簡化了控制平面的部署、管理、擴充套件和修補/更新。由於它建立在高度可用的初始種子叢集之上,我們可以避免芽叢集控制平面所需的多個仲裁主節點,從而減少浪費/成本。此外,實際的芽叢集僅由工作節點組成,可以授予其所有者完全管理訪問許可權,從而構建必要的職責分離以提供更高級別的 SLO。因此,架構角色和操作所有權定義如下(參見`圖 1`):
- Kubernetes 即服務提供商擁有、運營和管理花園叢集和種子叢集。它們代表所需景觀/基礎設施的一部分。
- 芽叢集的控制平面在種子叢集中執行,因此在服務提供商的獨立安全域內執行。
- 芽叢集的機器在客戶的雲提供商賬戶和環境中執行,由客戶擁有,但仍由 Gardener 管理。
- 對於本地或私有云場景,種子叢集(和 IaaS)的所有權和管理委託是可行的。
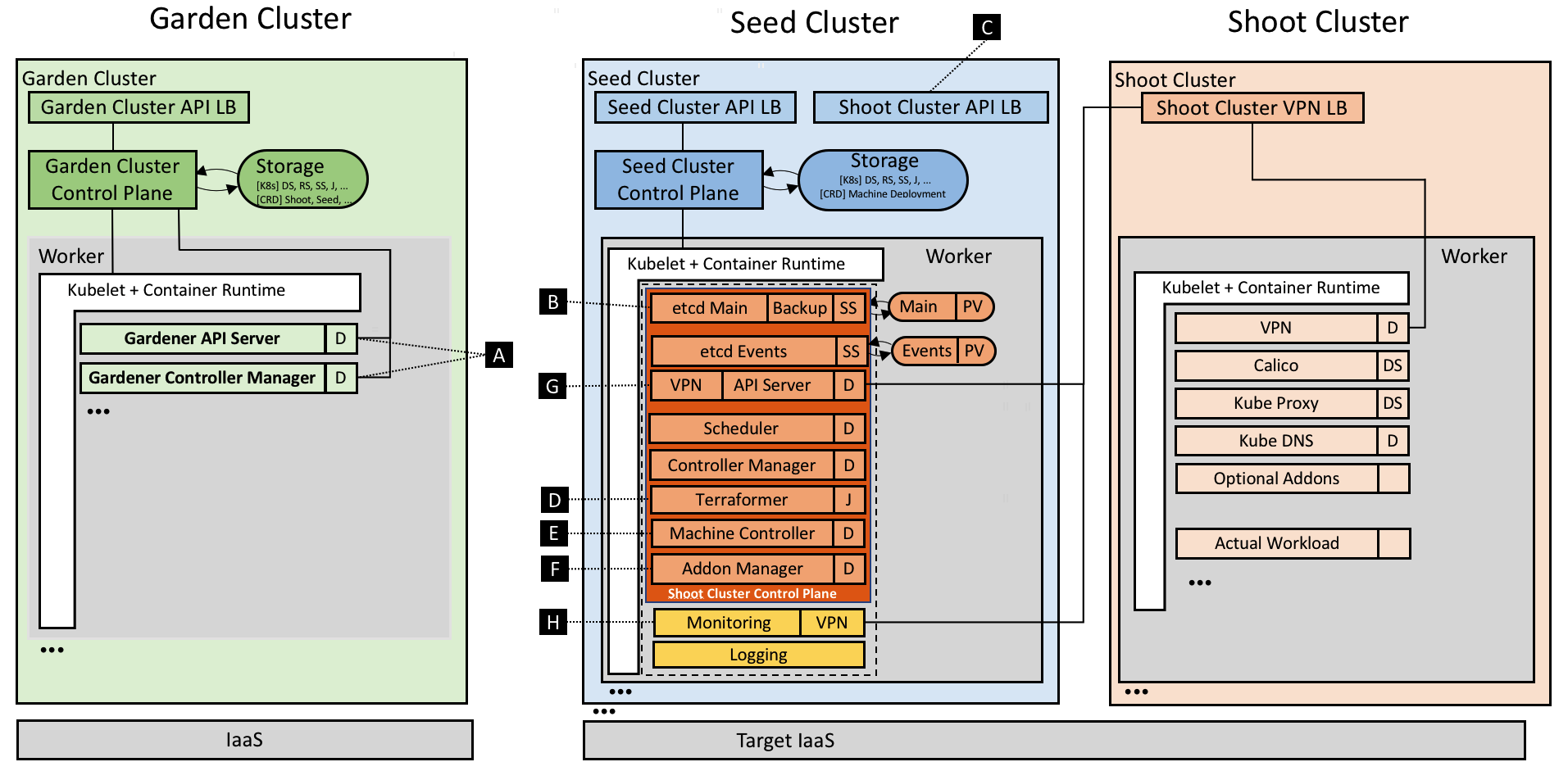
圖 1 包含元件的 Gardener 技術景觀。
Gardener 作為聚合 API 伺服器開發,並帶有一組捆綁的控制器。它在另一個專用的 Kubernetes 叢集(稱為“花園”叢集)中執行,並透過自定義資源擴充套件 Kubernetes API。最重要的是,Shoot 資源允許以宣告方式描述使用者 Kubernetes 叢集的整個配置。相應的控制器將像原生的 Kubernetes 控制器一樣,監視這些資源並將世界的實際狀態帶到所需狀態(導致建立、協調、更新、升級或刪除操作)。以下示例清單顯示了需要指定的內容:
apiVersion: garden.sapcloud.io/v1beta1
kind: Shoot
metadata:
name: dev-eu1
namespace: team-a
spec:
cloud:
profile: aws
region: us-east-1
secretBindingRef:
name: team-a-aws-account-credentials
aws:
machineImage:
ami: ami-34237c4d
name: CoreOS
networks:
vpc:
cidr: 10.250.0.0/16
...
workers:
- name: cpu-pool
machineType: m4.xlarge
volumeType: gp2
volumeSize: 20Gi
autoScalerMin: 2
autoScalerMax: 5
dns:
provider: aws-route53
domain: dev-eu1.team-a.example.com
kubernetes:
version: 1.10.2
backup:
...
maintenance:
...
addons:
cluster-autoscaler:
enabled: true
...
一旦傳送到花園叢集,Gardener 將接收它並配置實際的芽叢集。上面未顯示的是,每個操作都會豐富 `Shoot` 的 `status` 欄位,指示當前是否有操作正在執行並記錄上次錯誤(如果有)以及相關元件的執行狀況。使用者能夠以真正的 Kubernetes 風格配置和監控其叢集的狀態。我們的使用者甚至編寫了他們自己的自定義控制器來監視和修改這些 `Shoot` 資源。
技術深度探討
Gardener 實現了 Kubernetes 啟動方法;因此,它利用 Kubernetes 的能力來執行其操作。它提供了幾個控制器(參見 `[A]`)來監視 `Shoot` 資源,其中主控制器負責建立、更新和刪除等標準操作。另一個名為“芽護理”的控制器執行定期健康檢查和垃圾回收,而第三個控制器(“芽維護”)的任務是涵蓋諸如將芽的機器映像更新到最新可用版本等操作。
對於每個芽,Gardener 在種子叢集中建立一個專用的 `Namespace`,並帶有適當的安全策略,並在其中預先建立稍後作為 `Secrets` 管理的所需證書。
etcd
Kubernetes 叢集的後端資料儲存 etcd(參見 `[B]`)部署為具有一個副本和 `PersistentVolume(Claim)` 的 `StatefulSet`。我們遵循最佳實踐,執行另一個 etcd 分片例項來儲存芽的 `Events`。無論如何,主 etcd Pod 都透過一個側車進行了增強,該側車驗證靜態資料並定期拍攝快照,然後高效地備份到物件儲存。如果 etcd 的資料丟失或損壞,側車會從最新可用快照中恢復資料。我們計劃開發增量/連續備份,以避免恢復時(在恢復情況下)已恢復的 etcd 狀態與實際狀態之間出現差異 [1]。
Kubernetes 控制平面
如上所述,我們將其他 Kubernetes 控制平面元件放入原生 `Deployments` 中,並使用滾動更新策略執行它們。透過這樣做,我們不僅可以利用 Kubernetes 現有的部署和更新能力,還可以利用其監控和活躍度能力。雖然控制平面本身使用叢集內通訊,但 API 伺服器的 `Service` 透過負載均衡器暴露以進行外部通訊(參見 `[C]`)。為了統一生成部署清單(主要取決於 Kubernetes 版本和雲提供商),我們決定使用 Helm chart,而 Gardener 只利用 Tiller 的渲染能力,但直接部署生成的清單,根本不執行 Tiller [2]。
基礎設施準備
建立叢集的首要要求之一是在雲提供商端準備完善的基礎設施,包括網路和安全組。在我們當前的 Gardener 提供商特定樹內實現(稱為“植物學家”)中,我們使用 Terraform 來完成此任務。Terraform 為主要的雲提供商提供了很好的抽象,並實現了並行性、重試機制、依賴圖、冪等性等功能。然而,我們發現 Terraform 在錯誤處理方面具有挑戰性,並且它不提供技術介面來提取錯誤的根本原因。目前,Gardener 根據芽規範生成 Terraform 指令碼,並將其儲存在種子叢集相應名稱空間中的 `ConfigMap` 中。Terraformer 元件然後作為 `Job` 執行(參見 `[D]`),執行掛載的 Terraform 配置,並將生成的स्टेट寫回到另一個 `ConfigMap` 中。以這種方式使用 Job 原語有助於繼承其重試邏輯,並實現對臨時連線問題或資源限制的容錯。此外,Gardener 只需訪問種子叢集的 Kubernetes API 即可為底層 IaaS 提交 Job。這種設計對於通常不公開 IaaS API 的私有云場景非常重要。
機器控制器管理器
接下來需要的是用於排程叢集實際工作負載的節點。然而,Kubernetes 不提供請求節點的原語,這迫使叢集管理員使用外部機制。考慮因素包括完整的生命週期,從初始供應開始,到提供安全修復、執行健康檢查和滾動更新。雖然我們最初使用例項化靜態機器或利用雲提供商的例項模板來建立工作節點,但我們得出結論(也基於我們之前運行雲平臺的生產經驗),這種方法需要大量的努力。在 KubeCon 2017 的討論中,我們認識到管理叢集節點的最佳方法當然是再次應用核心 Kubernetes 概念,並教導系統自我管理它執行的節點/機器。為此,我們開發了 機器控制器管理器(參見 `[E]`),它透過 `MachineDeployment`、`MachineClass`、`MachineSet` 和 `Machine` 資源擴充套件了 Kubernetes,並支援在 Kubernetes 上下文中宣告式管理(虛擬)機器,就像 `Deployments`、`ReplicaSets` 和 `Pods` 一樣。我們重用了現有 Kubernetes 控制器的程式碼,只需抽象一些 IaaS/雲提供商特定的方法,用於在專用驅動程式中建立、刪除和列出機器。比較 Pod 和機器時,一個微妙的區別變得顯而易見:建立虛擬機器直接導致成本,如果發生意外情況,這些成本會迅速增加。為了防止這種失控,機器控制器管理器帶有一個安全控制器,可以終止孤立的機器,並凍結超出特定閾值和超時的 `MachineDeployment` 和 `MachineSet` 的推出。此外,我們利用現有的官方 叢集自動伸縮器,它已經包含了確定哪個節點池應該擴容或縮容的複雜邏輯。由於其雲提供商介面設計良好,我們使自動伸縮器能夠在觸發擴容或縮容時直接修改相應 `MachineDeployment` 資源中的副本數量。
附加元件
除了提供正確設定的控制平面外,每個 Kubernetes 叢集都需要一些系統元件才能工作。通常,這些是 kube-proxy、疊加網路、叢集 DNS 和入口控制器。除此之外,Gardener 允許訂購使用者可在芽資源定義中配置的可選附加元件,例如 Heapster、Kubernetes Dashboard 或 Cert-Manager。同樣,Gardener 透過 Helm chart 渲染所有這些元件的清單(部分改編並精選自 上游 charts 倉庫)。但是,這些資源在芽叢集中進行管理,因此具有完全管理訪問許可權的使用者可以對其進行調整。因此,Gardener 透過利用現有的看門狗 kube-addon-manager(參見 `[F]`)來確保這些部署的資源始終與計算/期望的配置匹配。
網路隔離
雖然芽叢集的控制平面執行在由友好的平臺提供商管理和提供的種子叢集中,但工作節點通常部署在使用者獨立的雲提供商(計費)賬戶中。通常,這些工作節點放置在私有網路中 [3],種子控制平面中的 API 伺服器使用基於 ssh 的簡單 VPN 解決方案(參見 `[G]`)與這些網路建立直接通訊。我們最近已將基於 SSH 的實現遷移到基於 OpenVPN 的實現,這顯著增加了網路頻寬。
監控與日誌
監控、警報和日誌對於監督叢集並保持其健康至關重要,以避免中斷和其他問題。Prometheus 已成為 Kubernetes 領域最常用的監控系統。因此,我們在每個種子的 `garden` 名稱空間中部署一箇中央 Prometheus 例項。它從所有種子的 kubelet 收集指標,包括在種子叢集中執行的所有 pod 的指標。此外,在每個控制平面旁邊,都會為芽本身提供一個專用的租戶 Prometheus 例項(參見 `[H]`)。它收集其自身控制平面以及在芽的工作節點上執行的 pod 的指標。前者是透過從中央 Prometheus 的聯邦端點獲取資料並過濾特定芽的相關控制平面 pod 來完成的。除此之外,Gardener 部署了兩個 kube-state-metrics 例項,一個負責控制平面,一個負責工作負載,暴露叢集級指標以豐富資料。節點匯出器提供更詳細的節點統計資訊。專用的租戶 Grafana 儀表板透過清晰的儀表板顯示分析和見解。我們還為關鍵事件定義了警報規則,並使用 AlertManager 在觸發任何警報時向操作員和支援團隊傳送電子郵件。
[1] 這也是不支援時間點恢復的原因。到目前為止,Kubernetes 中尚未實現可靠的基礎設施協調。因此,在不重新整理相關叢集的實際工作負載和狀態的情況下從舊備份恢復通常沒有多大幫助。
[2] 這個決定最相關的標準是 Tiller 需要一個埠轉發連線進行通訊,我們發現這對於我們的自動化用例來說過於不穩定和容易出錯。儘管如此,我們期待 Helm v3 能夠透過 `CustomResourceDefinitions` 與 Tiller 互動。
[3] Gardener 提供使用 Terraformer 建立和準備這些網路,或者可以指示它重用現有網路。
可用性和互動
儘管管理 Gardener 只需使用熟悉的 `kubectl` 命令列工具,但我們提供了一箇中央儀表板以方便互動。它使使用者可以輕鬆跟蹤其叢集的健康狀況,並使操作員能夠監控、除錯和分析他們負責的叢集。芽叢集被分組到邏輯專案中,團隊可以在其中協作管理一組叢集,甚至可以透過整合的票務系統(例如 GitHub Issues)跟蹤問題。此外,儀表板還幫助使用者新增和管理其基礎設施賬戶的 Secret,並在一個地方檢視所有芽叢集最相關的資料,同時獨立於它們部署到的雲提供商。
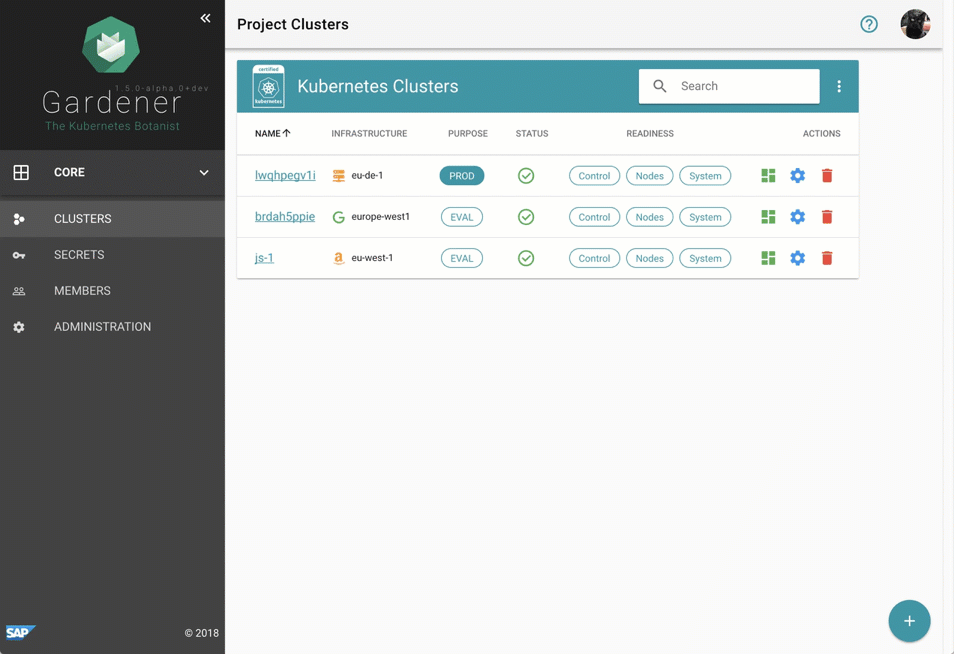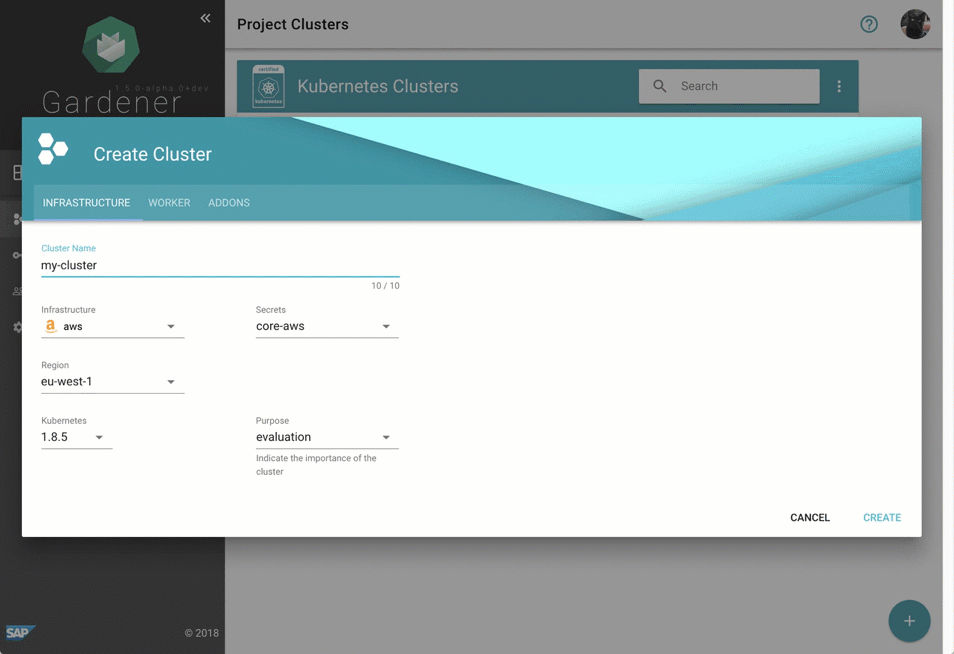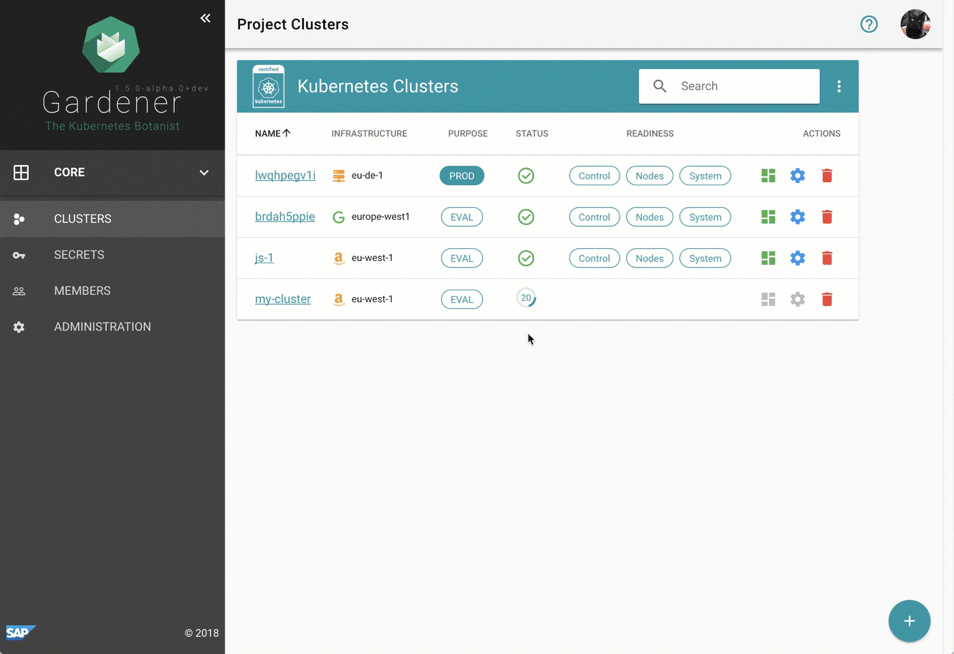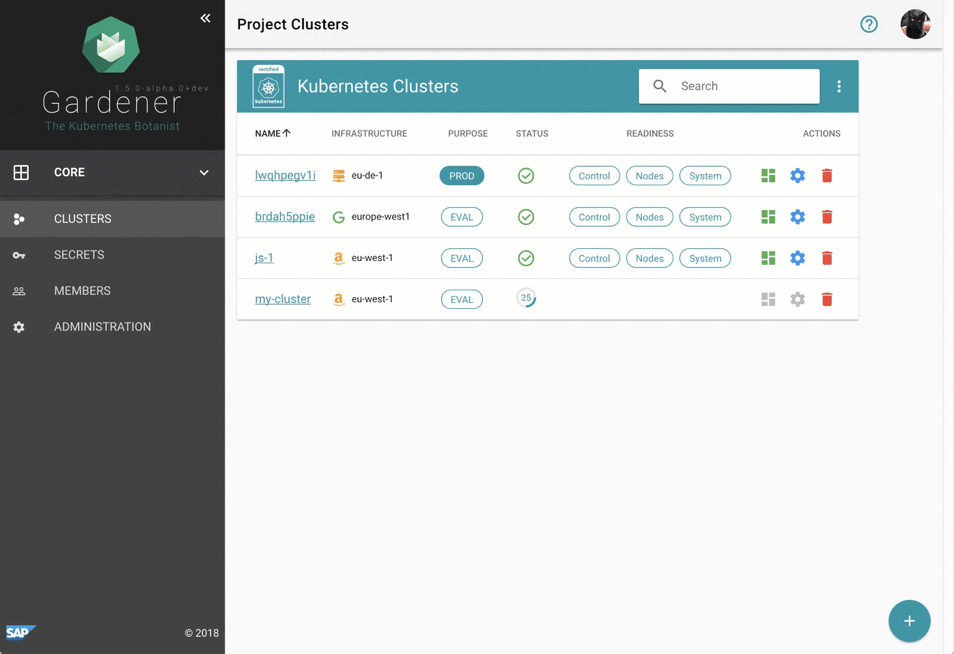
圖 2 動畫 Gardener 儀表板。
更側重於開發人員和操作員的職責,Gardener 命令列客戶端 `gardenctl` 透過引入簡單的、高級別的抽象和簡單的命令來簡化管理任務,這些命令有助於從大量種子叢集和芽叢集中整合和多路複用資訊和操作。
$ gardenctl ls shoots
projects:
- project: team-a
shoots:
- dev-eu1
- prod-eu1
$ gardenctl target shoot prod-eu1
[prod-eu1]
$ gardenctl show prometheus
NAME READY STATUS RESTARTS AGE IP NODE
prometheus-0 3/3 Running 0 106d 10.241.241.42 ip-10-240-7-72.eu-central-1.compute.internal
URL: https://user:password@p.prod-eu1.team-a.seed.aws-eu1.example.com
展望與未來計劃
Gardener 已經能夠管理 AWS、Azure、GCP、OpenStack 上的 Kubernetes 叢集 [4]。實際上,由於它只依賴於 Kubernetes 原語,因此它很好地滿足了私有云或本地要求。從 Gardener 的角度來看,唯一的區別是底層基礎設施的質量和可擴充套件性——Kubernetes 的通用語言確保了我們方法的強大可移植性保證。
然而,挑戰依然存在。我們正在探討在此開源專案中包含一個選項的可能性,以建立聯合控制平面,委託給多個芽叢集。在前面的部分中,我們沒有解釋如何引導花園叢集和種子叢集本身。您確實可以使用任何生產就緒的叢集配置工具或雲提供商的 Kubernetes 即服務產品。我們已經構建了一個基於 Terraform 的統一工具 Kubify,並重用了許多提及的 Gardener 元件。我們設想所需的 Kubernetes 基礎設施能夠透過初始引導 Gardener 完全生成,並且我們已經在討論如何實現這一點。
我們關注的另一個重要話題是災難恢復。當種子叢集發生故障時,使用者的靜態工作負載將繼續執行。然而,管理叢集將不再可能。我們正在考慮將受災芽叢集的控制平面遷移到另一個種子叢集。從概念上講,這種方法是可行的,我們已經具備了實施所需元件,例如自動化 etcd 備份和恢復。這個專案的貢獻者不僅有為生產開發 Gardener 的任務,我們大多數人甚至以真正的 DevOps 模式執行它。我們完全信任 Kubernetes 的概念,並致力於遵循“自食其力”的方法。
為了實現 Botanists(其中包含基礎設施提供商特定的實現部分)更獨立的演進,我們計劃描述定義良好的介面,並將 Botanists 分解為自己的元件。這類似於 Kubernetes 目前正在對 cloud-controller-manager 所做的事情。目前,所有云特定功能都是核心 Gardener 儲存庫的一部分,這為擴充套件或支援新的雲提供商設定了軟障礙。
當我們看看芽叢集是如何實際配置的,我們需要獲得更多關於擁有數千個節點和 Pod(或更多)的真正大型叢集如何表現的經驗。我們可能需要為大型叢集部署(例如)API 伺服器和其他元件,以實現橫向擴充套件以分散負載。幸運的是,基於 Prometheus 的自定義指標的水平 Pod 自動伸縮將使我們的設定相對容易實現。此外,在我們的叢集上執行生產工作負載的團隊反饋說,Gardener 應該支援預先安排好的 Kubernetes QoS。毋庸置疑,我們的願望是整合並貢獻到 Kubernetes Autopilot 的願景。
[4] 原型已經驗證了電信雲和阿里雲。
Gardener 是開源的
Gardener 專案作為開源專案開發,並託管在 GitHub 上:https://github.com/gardener
SAP 自 2017 年年中開始致力於 Gardener 專案,並專注於構建一個易於演進和擴充套件的專案。因此,我們現在正在尋找更多的合作伙伴和貢獻者加入該專案。如上所述,我們完全依賴 Kubernetes 原語、附加元件和規範,並採納其創新的雲原生方法。我們期待與 Kubernetes 社群保持一致併為其做出貢獻。事實上,我們設想將整個專案貢獻給 CNCF。
目前,與社群合作的一個重要焦點是幾個月前成立的 SIG Cluster Lifecycle 中的 Cluster API 工作組。其主要目標是定義一個表示 Kubernetes 叢集的可移植 API。這包括控制平面和底層基礎設施的配置。我們將現有 Shoot 和 Machine 資源與社群正在開發的內容進行比較,重疊之處引人注目。因此,我們加入了這個工作組,並積極參與其定期會議,努力回饋我們從生產中獲得的經驗教訓。自私地說,塑造一個健壯的 API 也符合我們的利益。
如果您看到 Gardener 專案的潛力,請在 GitHub 上了解更多資訊,並透過提問、參與討論和貢獻程式碼來幫助我們改進 Gardener。另外,請嘗試我們的快速入門設定。
我們期待在那裡見到您!